1. 小游戏容器与游戏引擎
小游戏容器的设计上可以理解是一种特化版的 WebView,渲染上下文上裁剪了多余的 DOM Element,只保留 Canvas;而脚本引擎上则 JS Polyfill 或是容器 Binding 的方式去对齐 ECMA-262 的标准。此外容器还需要提供 Script 加载与执行、WASM 等新标准处理、以及 Audio 与 Video 等多媒体能力,这些能力都将通过 JSBinding 的形式,将接口包装成 BOM 的形式给到 JS 侧使用。
小游戏容器之所以要设计成符合 Web 标准的容器,是为了兼容不同游戏引擎。这种设计理念的本质是将底层平台能力标准化、通用化,把碎片化的硬件、系统能力屏蔽在容器内部,只向上提供一套与浏览器 BOM、DOM 类似的编程模型,使得各类游戏引擎(如 Cocos、Egret、Laya、Unity WebGL)都可以以 Web 的运行环境的方式接入,避免每个引擎都去适配各家平台的原生能力。这实际上是 WebView 本地化、轻量化的一次再演化,小游戏容器约等于一个轻量浏览器内核。
这个过程中容器负责“平台标准化”,引擎负责“内容生态”,比如
小游戏容器的职责:
- 提供统一的渲染上下文(Canvas/WebGL)。
- 提供统一的脚本运行时(JS/WASM)。
- 提供标准化的输入、音频、视频、多媒体 API。
- 提供网络、存储、支付、分享、广告等平台能力封装。
- 对接安全沙箱、权限管理、性能隔离等系统层。
游戏引擎的职责:
- 提供高层抽象的场景管理、物理引擎、动画、资源管理。
- 提供开发者友好的编辑器、调试工具链。
- 提供跨平台的组件化开发范式(UI、骨骼动画、粒子系统等)。
- 管理游戏生命周期、状态同步、渲染调度。
接下来,以 Cocos 引擎的渲染管线为例,介绍小游戏容器对资源的加载流程以及对游戏组件的渲染流程。
2. 游戏引擎中的三大循环
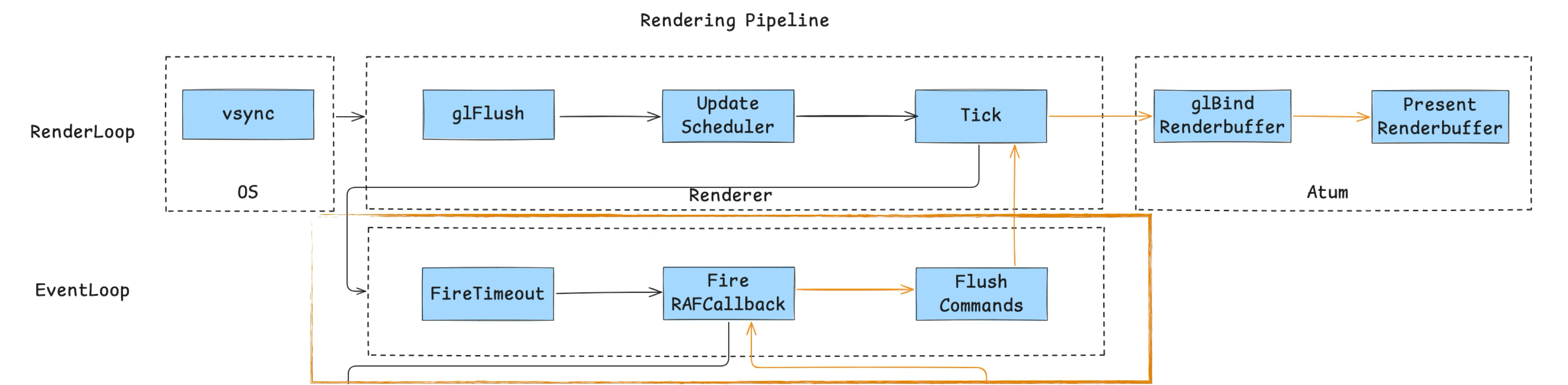
游戏引擎的渲染管线由三大循环进行驱动,分别是渲染循环、事件循环和游戏循环,以下是梳理出来的三大循环的全景图:
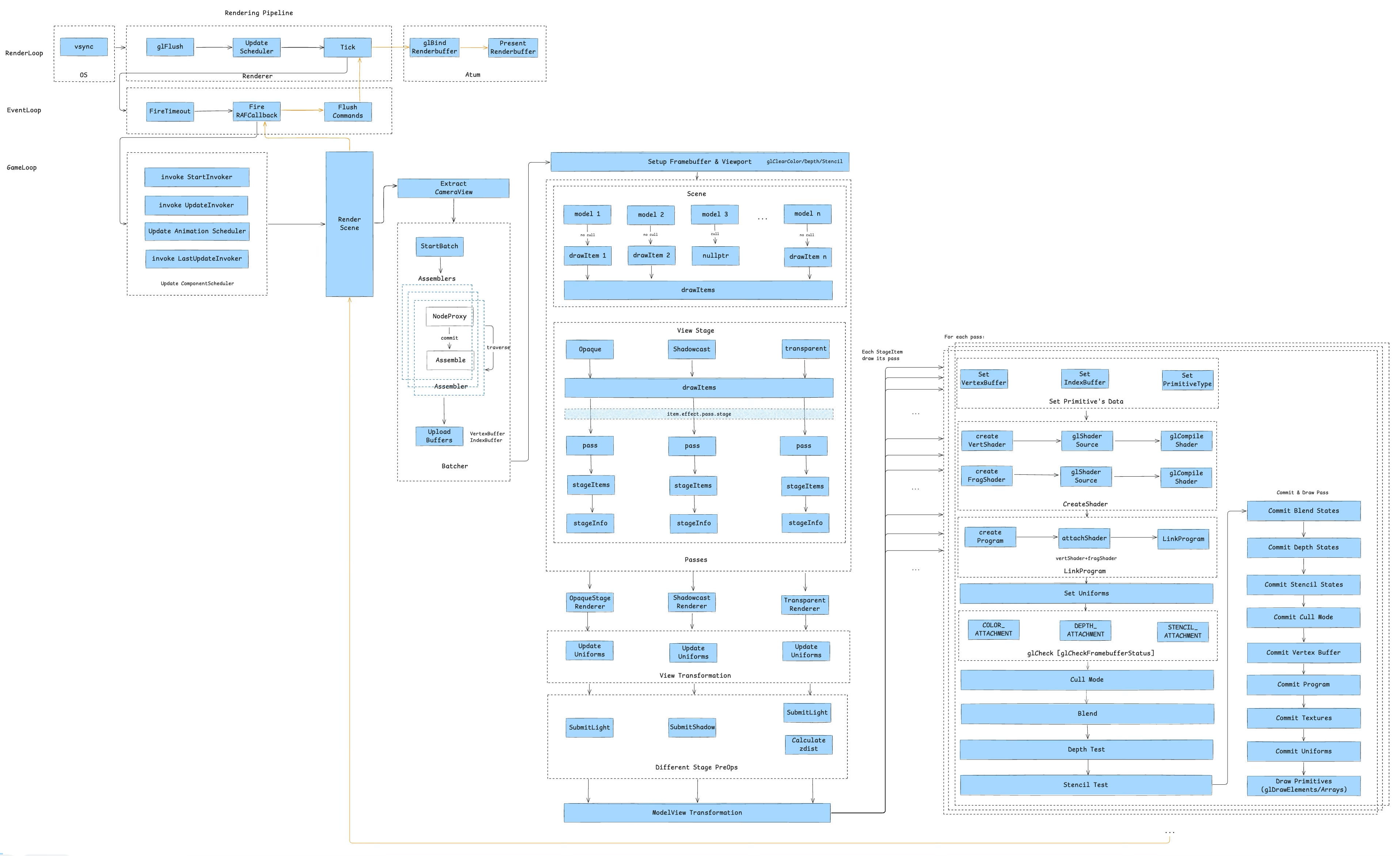
2.1 渲染循环 RenderLoop
首先是渲染循环,它的主流程如下图所示:

整个渲染循环由系统的 Vsync 信号驱动,iOS 由 CADisplayLink 发起,通过应用进程的主线程的 RunLoop 来执行渲染任务,具备一定的帧率控制能力,如 iOS 下可以设定 30/60/90/120 FPS。
在引擎侧,核心流程做了 3 件事:
glFlush清空 GL 缓冲指令:将上帧未执行的 OpenGL 指令强制刷新,确保显存与帧缓区数据一致,防止由于指令堆积导致的“帧延迟”或“卡顿”。UpdateScheduler异步任务调度:调度当前帧需要触发的异步任务,例如音频回调、网络事件响应等。保证非渲染逻辑(如数据更新)与渲染解耦,提高主线程并发能力。Tick驱动 JS 层逻辑:每帧通过 Binding 固定调用 JS 侧 Tick 方法,执行动画、状态更新等与渲染相关的逻辑。从而实现逻辑层与渲染层的解耦,增强跨平台的适配能力。
在容器侧,iOS 通过 CAEAGLayer 处理 GL 指令上屏,主要有两个步骤:
glBindRenderbuffer绑定 RenderBuffer:将当前帧渲染结果绑定至 RenderBuffer,作为上屏缓冲区。PresentRenderbuffer显示输出:将 RenderBuffer 内容呈现至屏幕,实现用户可见的最终画面。
在 iOS 渲染体系中,最终负责显示的组件是 CAEAGLLayer。它作为 Layer 树(Layer Tree) 的一部分,直接引用共享内存中的渲染缓冲区(Renderbuffer 数据)。与此同时,系统的 Compositor(合成器) 会将 CAEAGLLayer 的内容与其他 UI 元素(如 UIKit、SwiftUI)进行统一合成,最终输出到屏幕。
在每一帧的 Tick 任务 中,JavaScript 会与游戏引擎协作,生成本帧所需的 Framebuffer(详见 3.5 至 3.10 节)。此时,Core Animation 与 OpenGL ES 通过共享渲染缓冲区实现数据同步。这意味着,OpenGL 渲染结果实质上只是一块 Layer 树中的画布,最终仍需与系统 UI 层级一同被合成为最终显示图像。
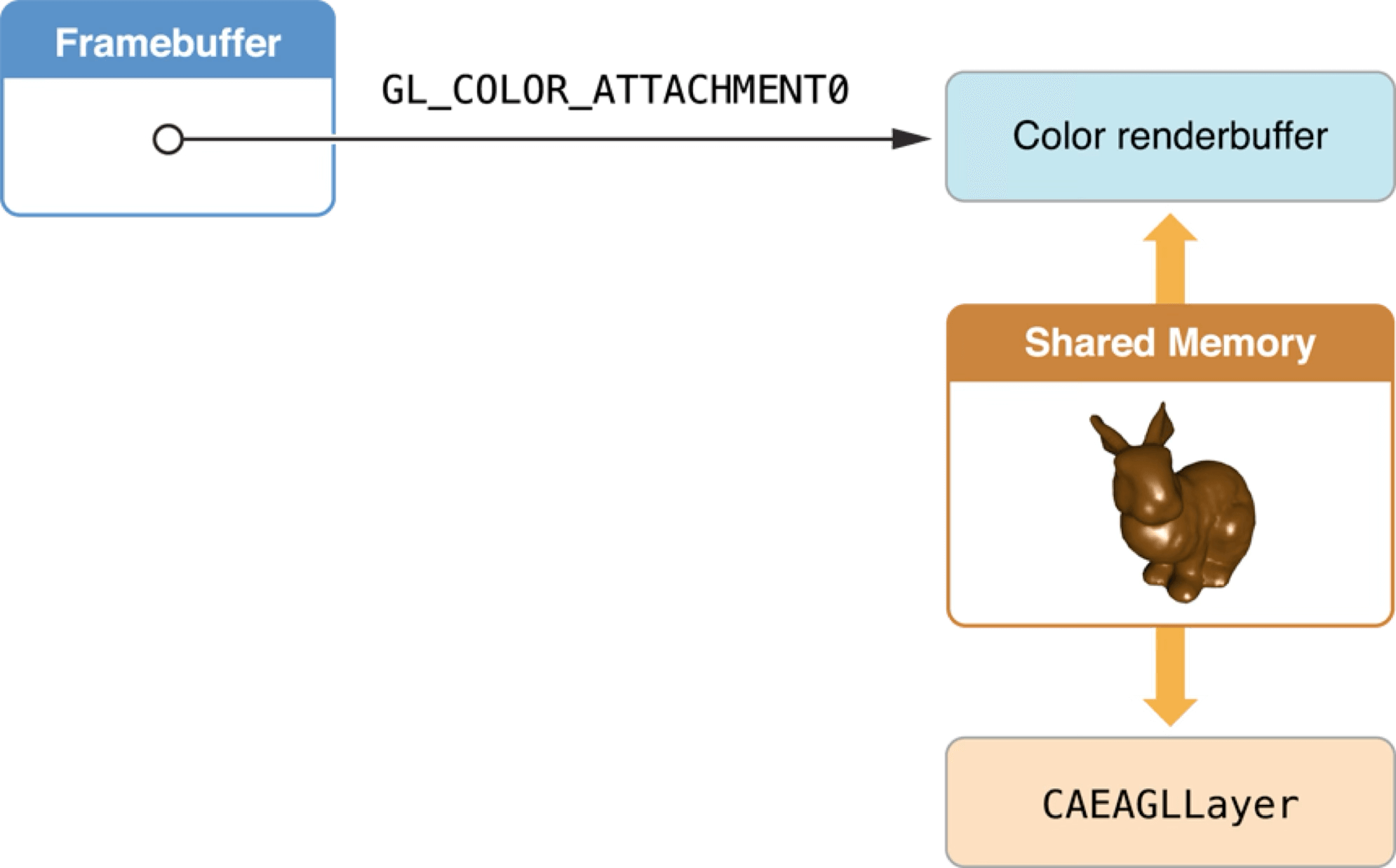
当然,本文中涉及的小游戏容器仅使用了 OpenGL 作为渲染后端,随着 Metal、Vulkan 等新一代图形 API 的兴起,RenderBuffer 绑定与上屏流程将更倾向“并行渲染 + 异步上屏”,提升高帧率下的流畅度与低延迟体验。 这个渲染循环的逻辑是同步执行的,因此如果将帧率设置为 60 FPS 时,以上所说的一帧的逻辑没有在 16.6ms 内运行完,便会导致 Jank。
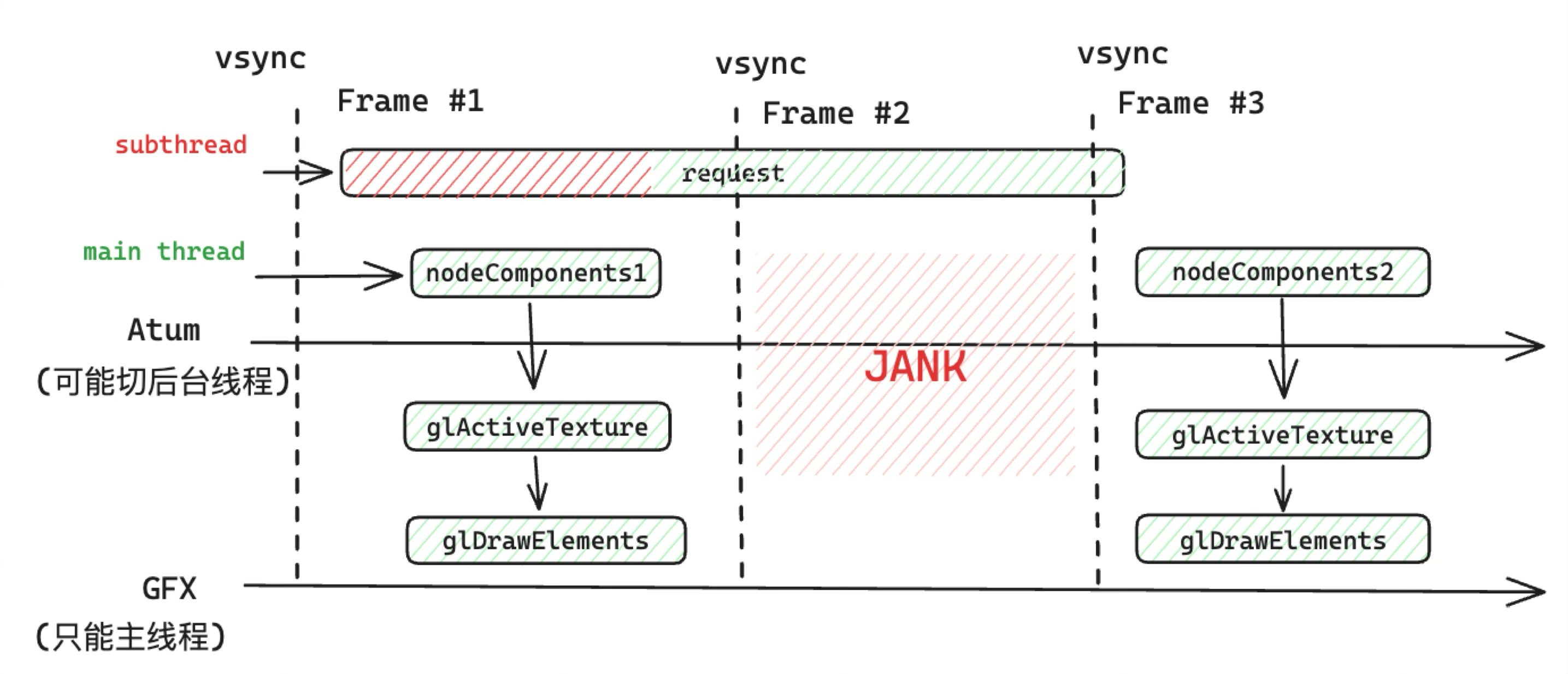
比如在这个 Bad case 中,运行 Tick 任务时,在主线程的 JS 执行了 136ms,就导致了游戏动画卡顿:
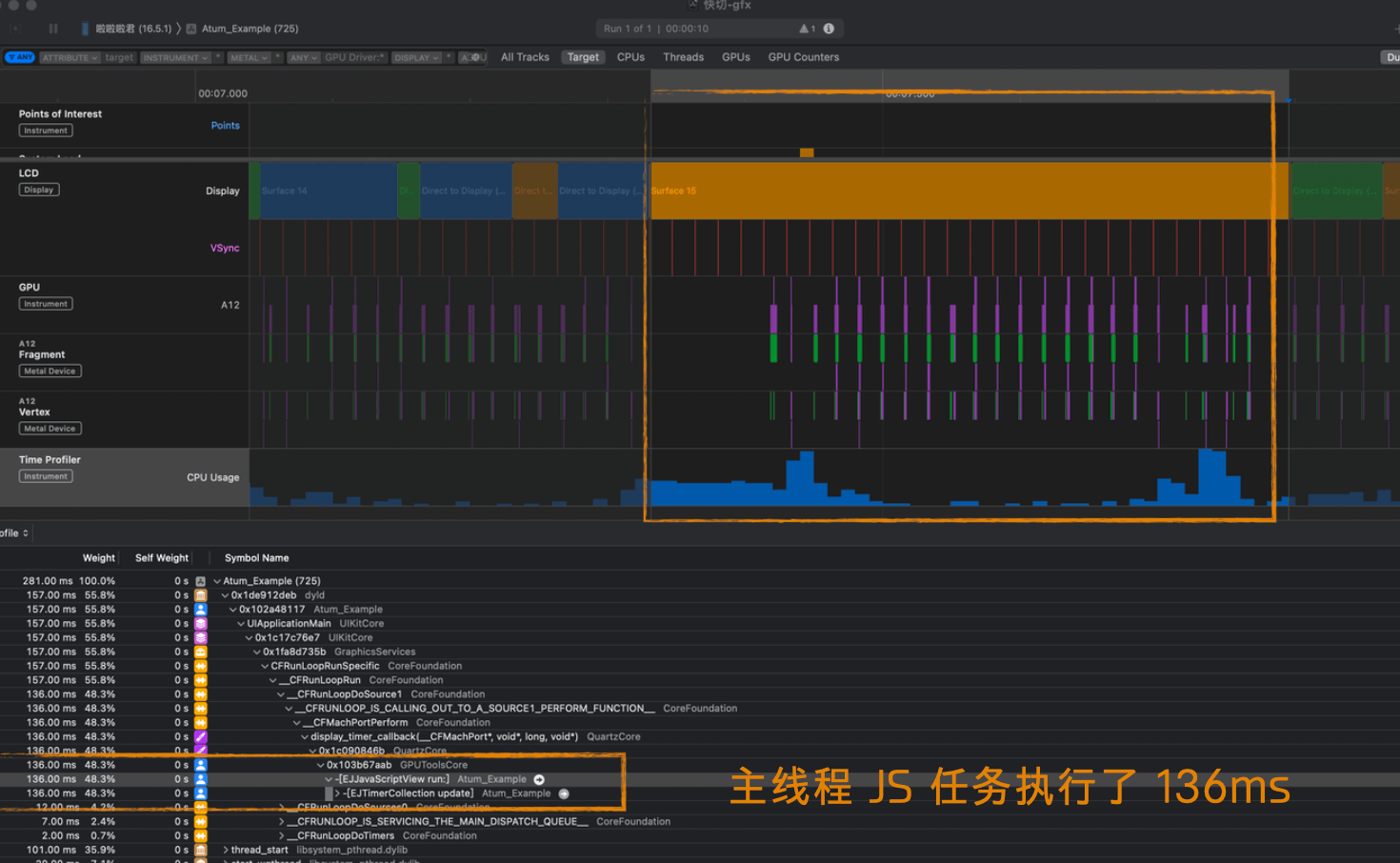
因此,为了保证游戏运行的流程性,意味着我们需要不停地打磨性能,尽可能降低同步任务的耗时。性能优化一定要借助 Profiling 工具,以下是一些常用的工具:
- Xcode GPU Frame Debugger:针对 iOS 平台的图形调试工具,能够深入分析 渲染管线级别的性能瓶颈,尤其适合 Metal 与 OpenGL ES 开发场景。
- RenderDoc:业界主流的跨平台图形调试工具,支持捕捉帧数据,分析渲染管线各阶段的资源与性能瓶颈,适用于 OpenGL、Vulkan、DirectX 等 API。
- inspector.js:Web 端可以使用,便于在 WebGL 场景下分析 DrawCall、着色器与资源绑定等性能数据。
- Mali offline shader compiler:https://zhuanlan.zhihu.com/p/161761815,适用于 ARM Mali GPU 的离线着色器编译与分析工具,可用于评估 Shader 复杂度与指令执行成本,优化移动端渲染性能。
- Snapdragon Profiler: 抓帧工具,支持统计 Heavy DrawCall 与 Overdraw,帮助识别渲染瓶颈与冗余计算。
2.2 事件循环 EventLoop
我们向下,从 Tick 任务进入到第二个循环 —— 事件循环。
因为小游戏容器不是 WebView,只有一个 JS 引擎,因此我们需要实现一个事件循环机制,驱动 JS 执行(不一定完全对齐浏览器标准,只需要满足容器要求即可)。由图可见,主要包括 3 个任务:
- 消费 timer 等宏任务:处理通过 setTimeout、setInterval 等方式注册的定时任务,确保定时逻辑的正确触发。
- 消费 rAF 任务:这一步主要是为了驱动 GameLoop 逻辑,游戏主循环通常挂载于 rAF 回调中,用于逐帧更新渲染与逻辑。
- 清空当前帧的 Commands:执行渲染命令、界面更新等待处理的指令,完成本帧渲染周期。
这里重点说一下 rAF 的实现。在早期,rAF 通过 setTimeout(0) 来模拟实现,链路如下:
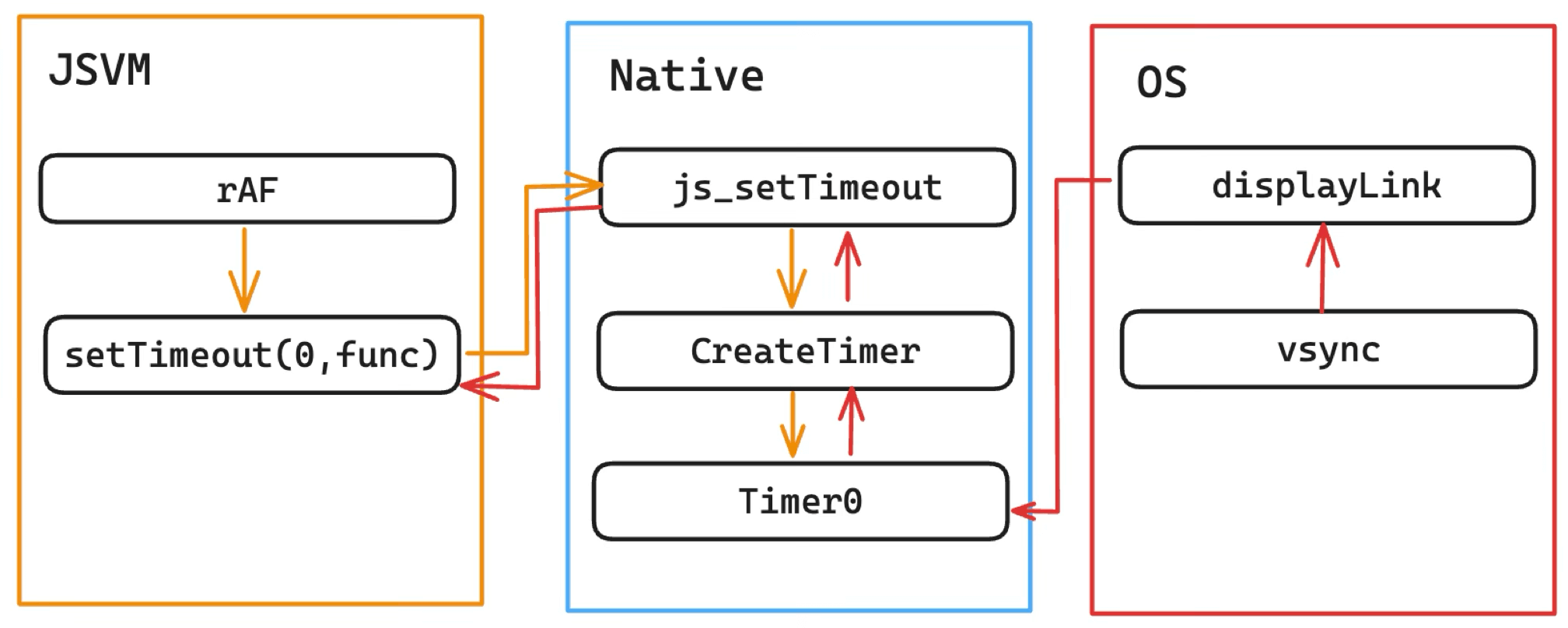
可以发现这里是存在问题的:
- 不合规范:是使用 setTimeout 0 模拟的,并非 vsync 直接驱动。
- 链路太长:Native 来维护 Timer 队列,等待 vsync 信号消费完之后再回调给 JS。
后来按照 WHATWG 标准进行了重构,
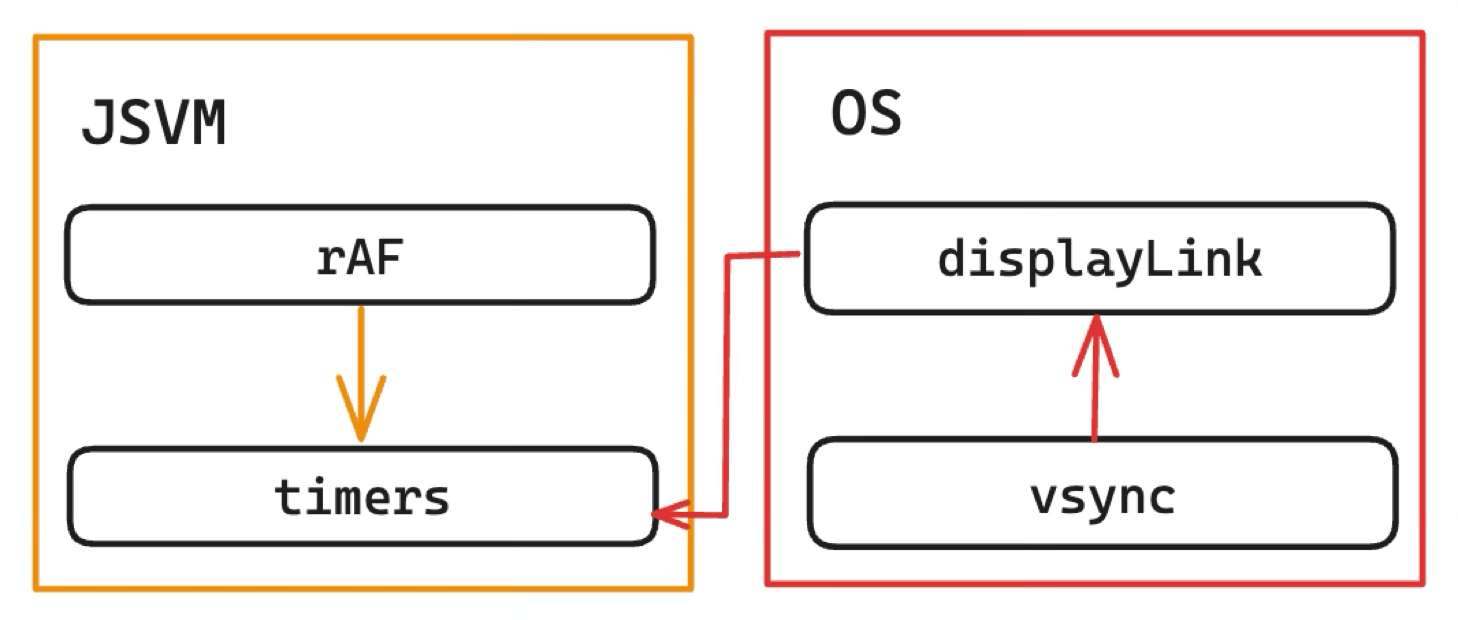
优点如下:
- 标准化:vsync 后直接触发 JS 的调用
- 开销小:JS 维护 Timers 队列,移除原生层中转的 JSBinding 调用开销。
可见渲染性能的优化,关乎在很多实现的细节上,需要挖掘与打磨。
最终,通过以上的事件循环,容器能够维持 JS 引擎与渲染系统之间的协同工作,实现游戏的持续运行与更新。
2.3 游戏循环 GameLoop
这一部分展开来说就是第 3 章——游戏组件的一生:
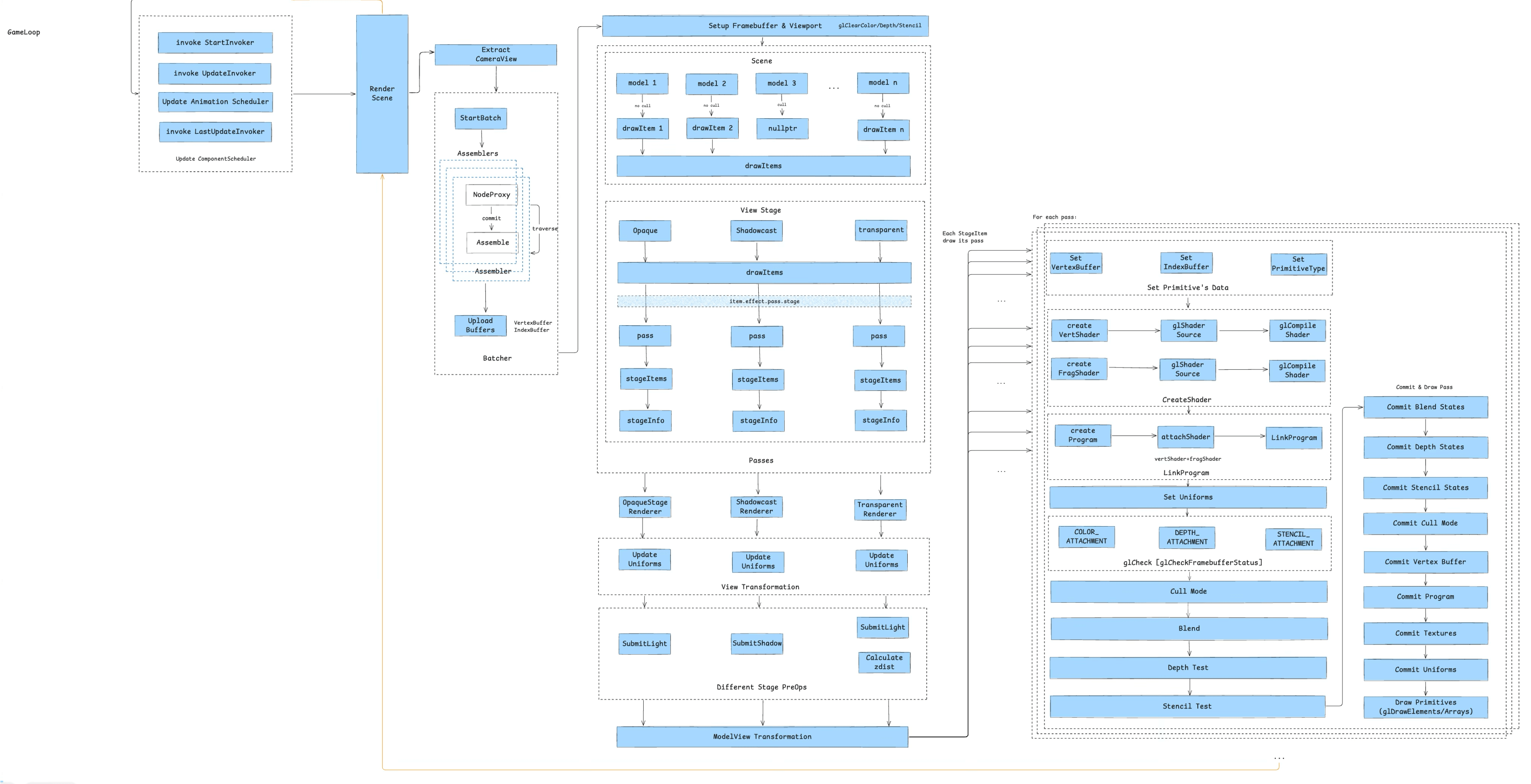
在展开画卷之前,介绍一下传统的使用 OpenGL 作为渲染后端的小游戏容器的渲染流程:
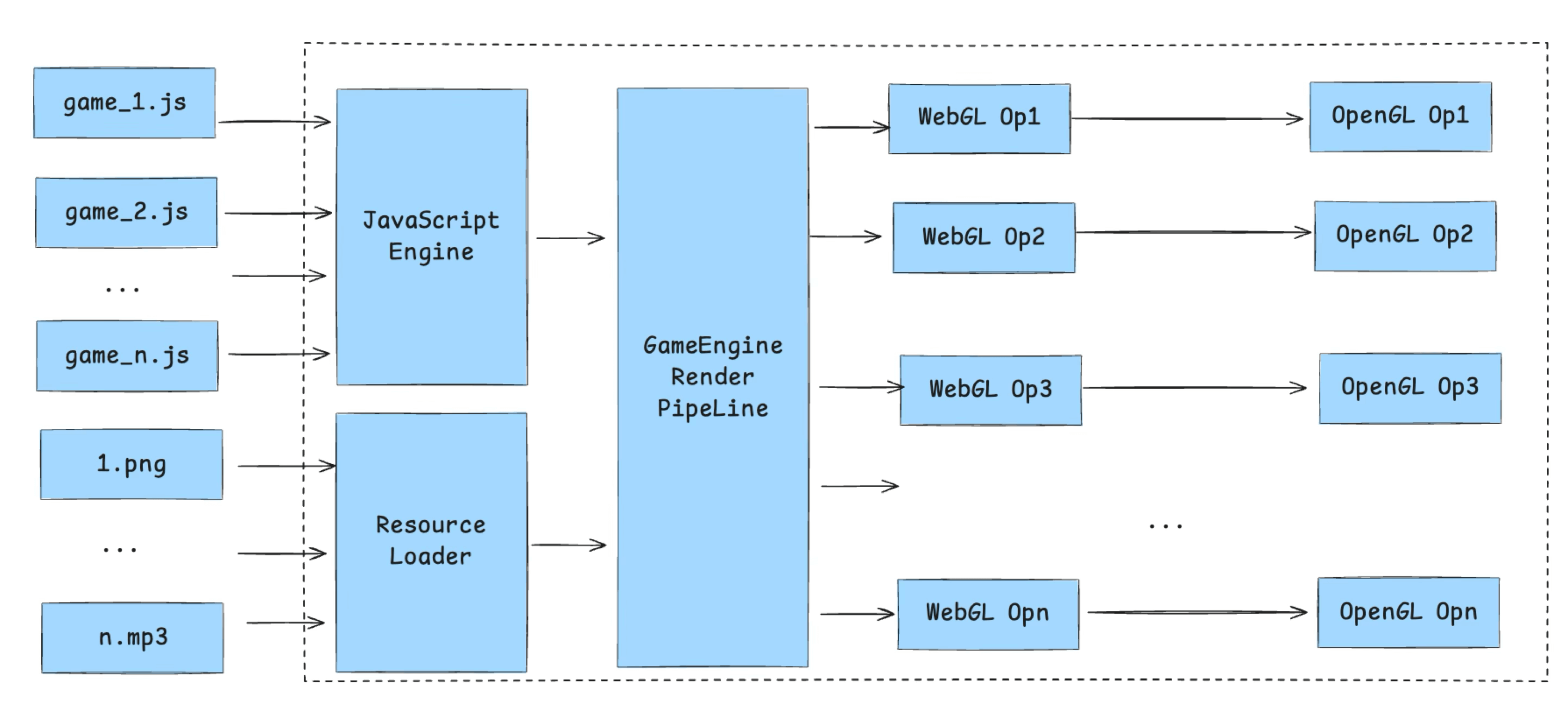
首先是资源加载,涉及到两种完全不同的资源处理——脚本资源和静态资源。脚本资源由 JS Runtime 进行处理,而静态资源则针对不同类型的文件又有各自的处理方案——包括图片、字体、音频、视频、还有比较特殊的骨骼动画。因为本文主要说渲染,就不展开介绍资源加载流程了。
之后,这些资源被游戏引擎渲染关键处理,由 JS 驱动生成 WebGL 指令,通过 JS Binding 最终调用到 C++ 或 Native 侧的 OpenGL 指令集上 —— WebGL 是 OpenGL 的子集,因此可以一一对应。
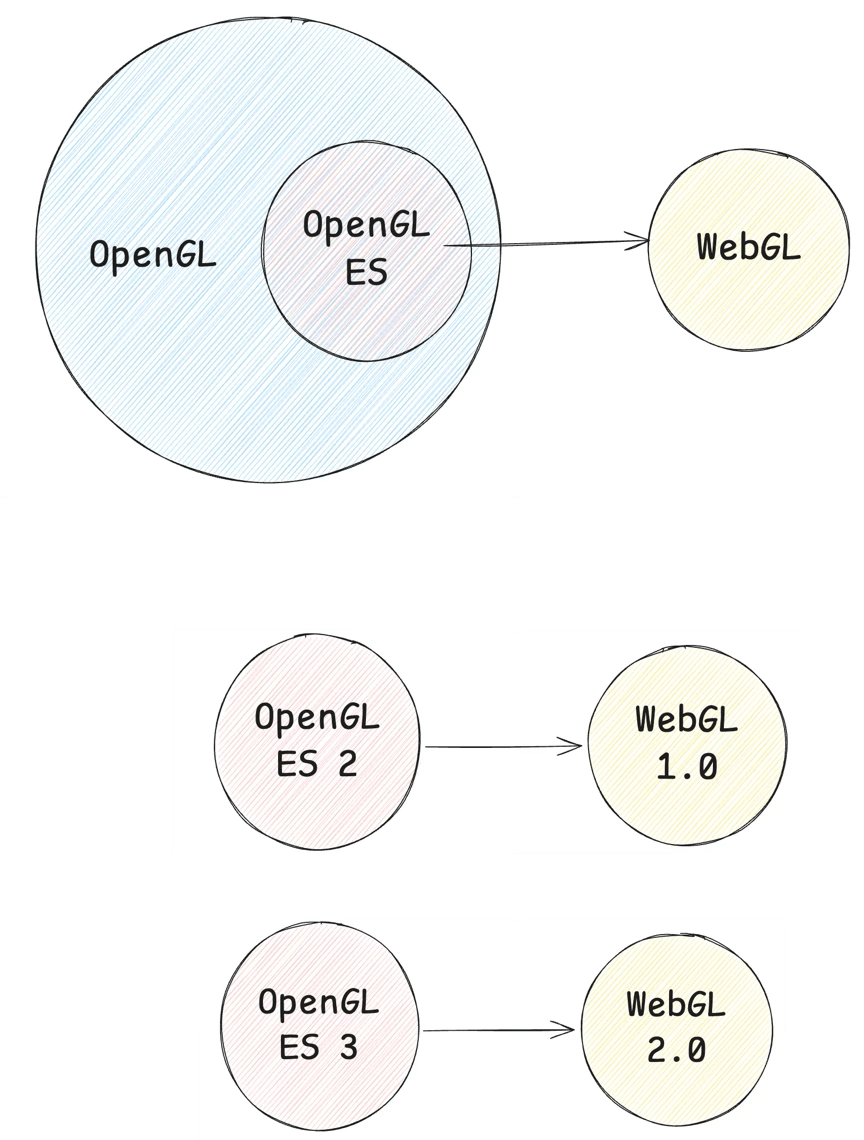
这个过程往往会出现很多渲染瓶颈,因此其中会涉及到很多优化项。我们根据硬件资源来看,主要关注 CPU、GPU 和带宽。而在当下移动端硬件资源并不富裕的场景下,对于游戏的优化,本质上变成了“平衡的艺术” —— 我们需要去平衡 CPU、GPU 和带宽资源。即如果瓶颈不能消灭,就需要转移瓶颈,比如经常见的是从 CPU 移到 GPU —— 使用 Computer Shader、GPU skinning、Animation Bake、GPU particles 等等。
对于 CPU,这是最常见的瓶颈。这里不展开说游戏业务侧的优化项(减少 DrawCall 的 Culling、Batching 这些),而是从容器侧提供一些优化思路。
- 比如上面的 JS Binding 调用可能会导致瓶颈,那我们可能会去做合批,从两方面去实现,一方面是调用次数合批,做 CommandBuffer 增加吞吐;另一方面可以做调用实现的合并,比如提供 GFX 高级图形库。
- 还比如一些 JS 同步任务会阻塞主线程,那么就把计算密集型的任务转到 Native 去做。
- 比如 JS 自身解释执行的执行效率,那就想办法用 JIT 或者 WASM。
- 再比如 GC 上,也有一些优化的地方。
对于 GPU,如果产生瓶颈了,一般是由于 Fragment Shader 指令太复杂,或者 Vertex Buffer 过大,比如 3D 渲染中的三角形面数超过阈值,一般移动端场景下需要控制在 50 万面到 150 万面之间。另外,高 Overdraw 也会导致 GPU 多做很多无用功。
对于带宽瓶颈,则主要是靠压缩纹理(桌面端还可以用延迟渲染和后处理技术)。在网上有这么一个结论:
如果你的游戏跑 60 帧,那么每帧可用的带宽将会是 21024/60 = 34M, 假设你的 GBuffer 的分辨率是 1280 \ 1080,那么写一次 GBuffer(RGBA 4 个字节)的带宽大小为: 12801080\4/1024/1024 = 5.2M, 如果 3 张则是 15.6M.
考虑到一般你的游戏都会有 Overdraw, 假设 Overdraw 比较合理在 1.5 左右,那么这样的带宽消耗就能占到 15.6 * 1.5 = 23.4 M。 考虑到你还要渲染场景,ui 和角色等内容,这样很容易就超过了每秒 34M 的推荐带宽占用。
下图是一个常见的同步渲染管线:
- 应用层提供顶点数据
- 构建顶点着色器对顶点进行标准化
- 图元装配构建几何图元
- 光栅化阶段,将图元离散化为片元,每个片元对应屏幕上的像素区域
- 片元着色器对每个片元执行纹理采样、颜色计算、雾效等像素级处理。
- 进行测试与混合操作(Alpha、深度、模板测试),并将结果写入帧缓冲区 Framebuffer。
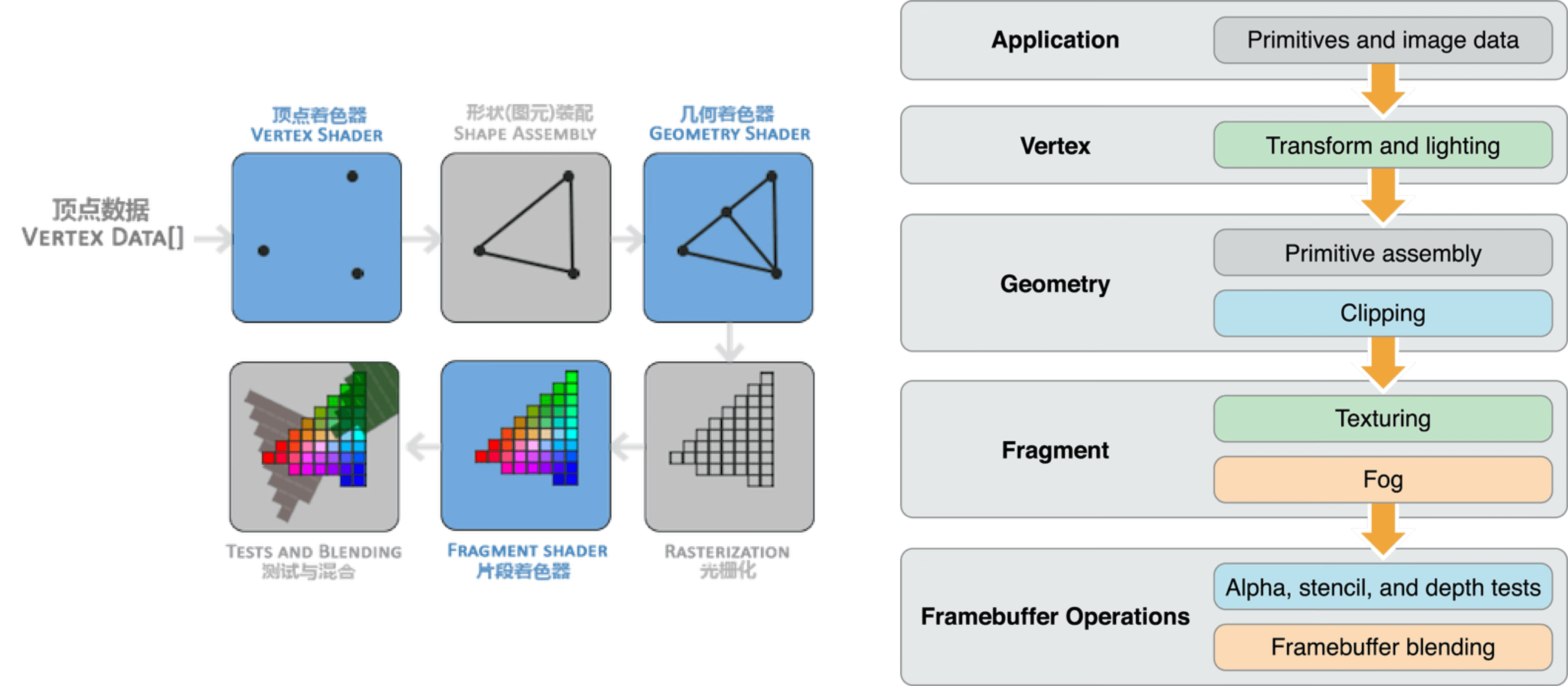
构建完 Framebuffer 后,就回到了我们 2.1 节所说的 CAEAGLLayer 绘制上屏了。
接下来,我们就展开画卷,看看游戏组件的一生。
3. 游戏组件的一生
对于游戏组件从加载到上屏的流程我画了一张图:
把这个流程可以简单拆成 10 个阶段:

为了介绍清楚这个流程,我准备了一个最简单的 Cocos 游戏 Demo。这个是 Demo 的场景设计:
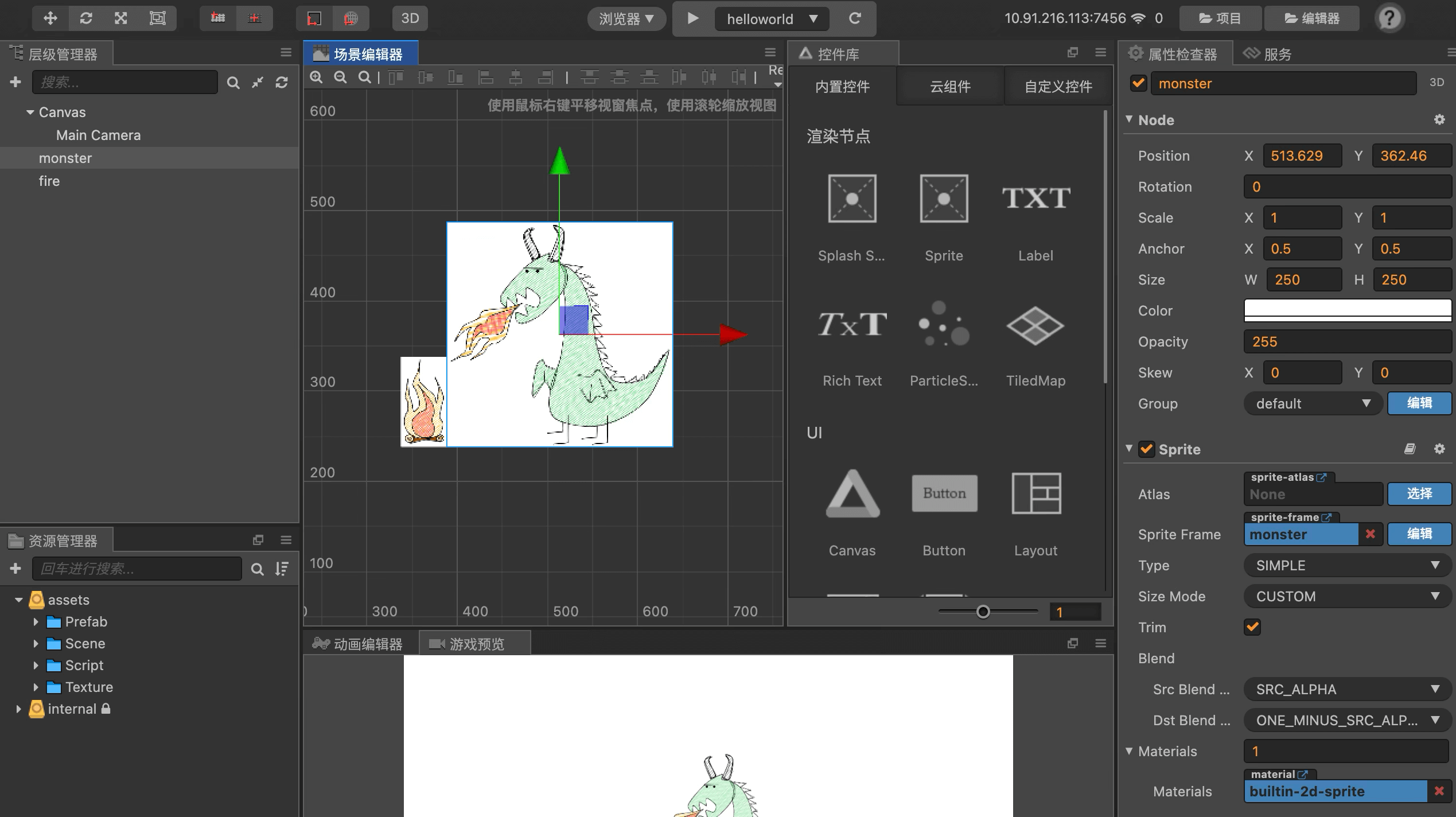
这个是主场景的代码:
const { ccclass } = cc._decorator;
@ccclass
export default class Helloworld extends cc.Component {
protected onLoad(): void {
console.log('onLoad');
}
start () {
console.log('Hello World');
}
}
3.1 Load Assets
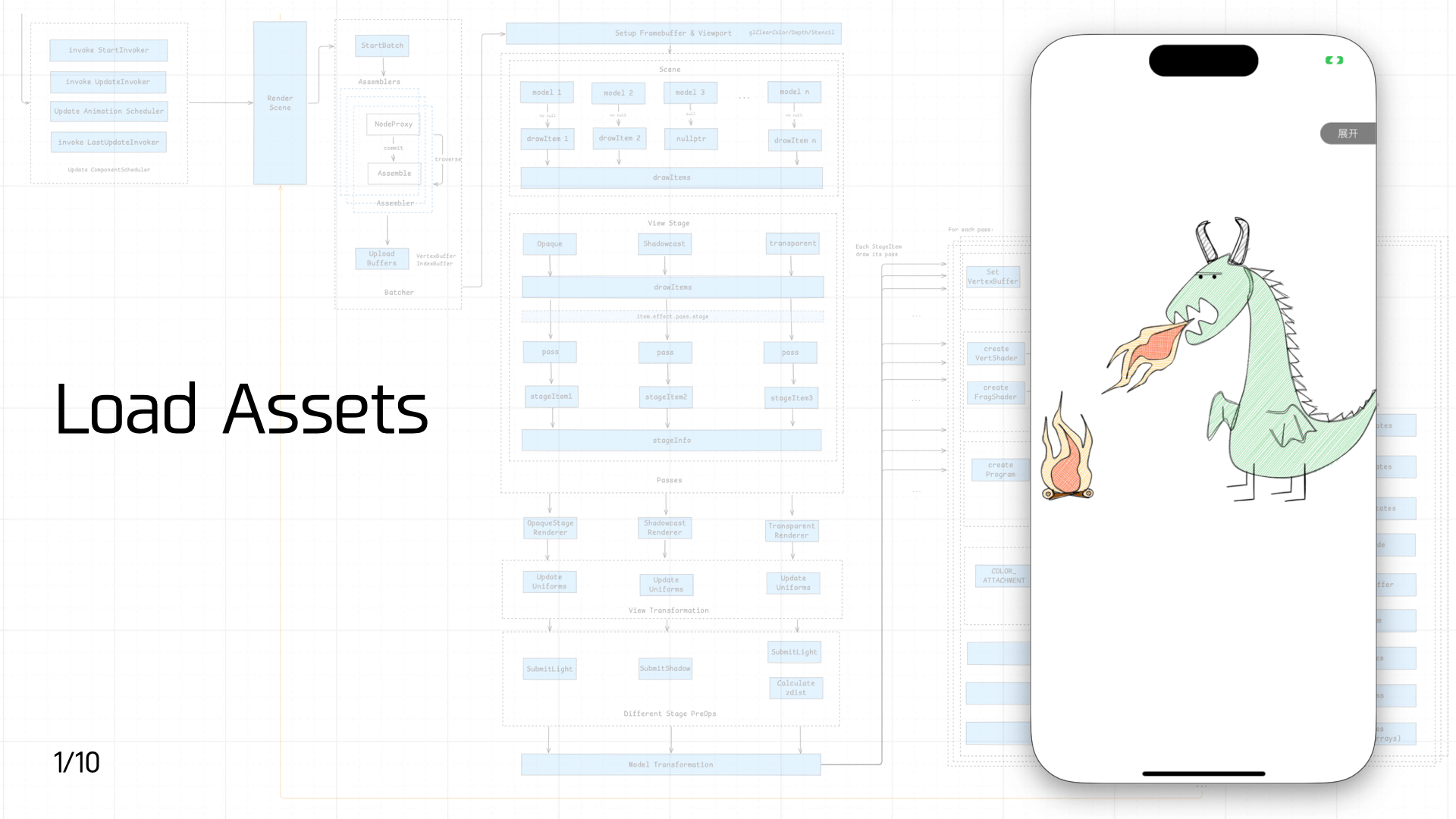
首先是资源加载,前文介绍过游戏资源可以分为静态资源和脚本资源。由于静态资源的加载流程涉及的内容太多了,本节只简单介绍下脚本资源加载。
包括 3 类脚本资源:
- 内置脚本:引擎启动的时候进行加载,包括注册 JS Binding、实现 window 对象(基础的 BOM 和 Canvas DOM 对象)、polyfill 补齐 ES 标准等等。这个脚本内置在容器里,容器启动 JS 引擎的时候直接加载。这一步可以做多实例和预执行,以加快启动速度。
- 入口脚本:容器需要一个入口脚本,类似与 Web 里的 HTML,以便引入游戏入口资源。
- 动态加载的脚本:由游戏入口资源引入,比如游戏框架代码、游戏包里的 JS 资源等等。
这里可以容器侧可以提供离线资源、preload、prefetch、预执行等方式进行优化,同时在 JS 引擎方面也可以扩展做下 Code Cache,避免重复的编译耗时。
3.2 Component Scheduler
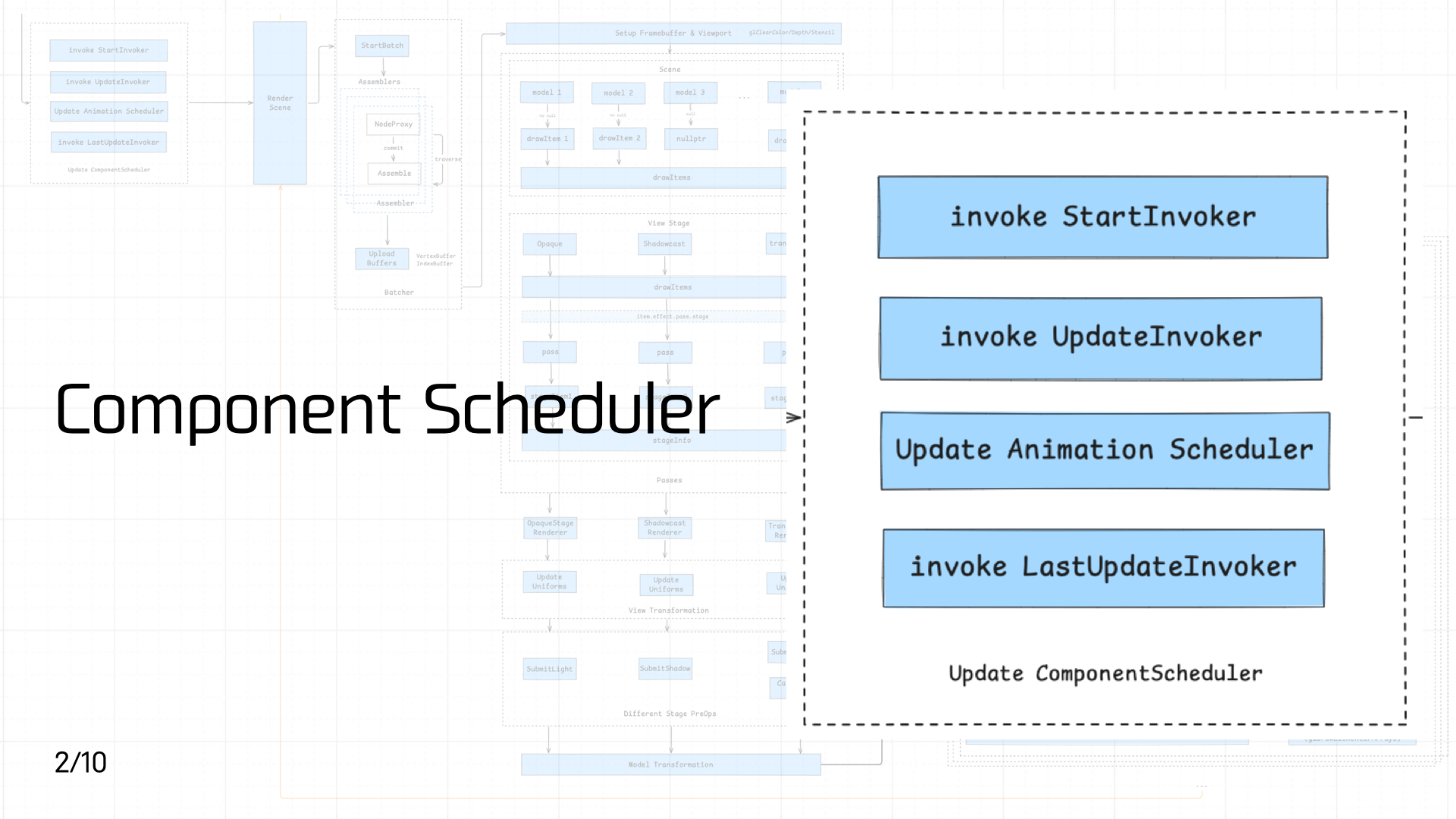
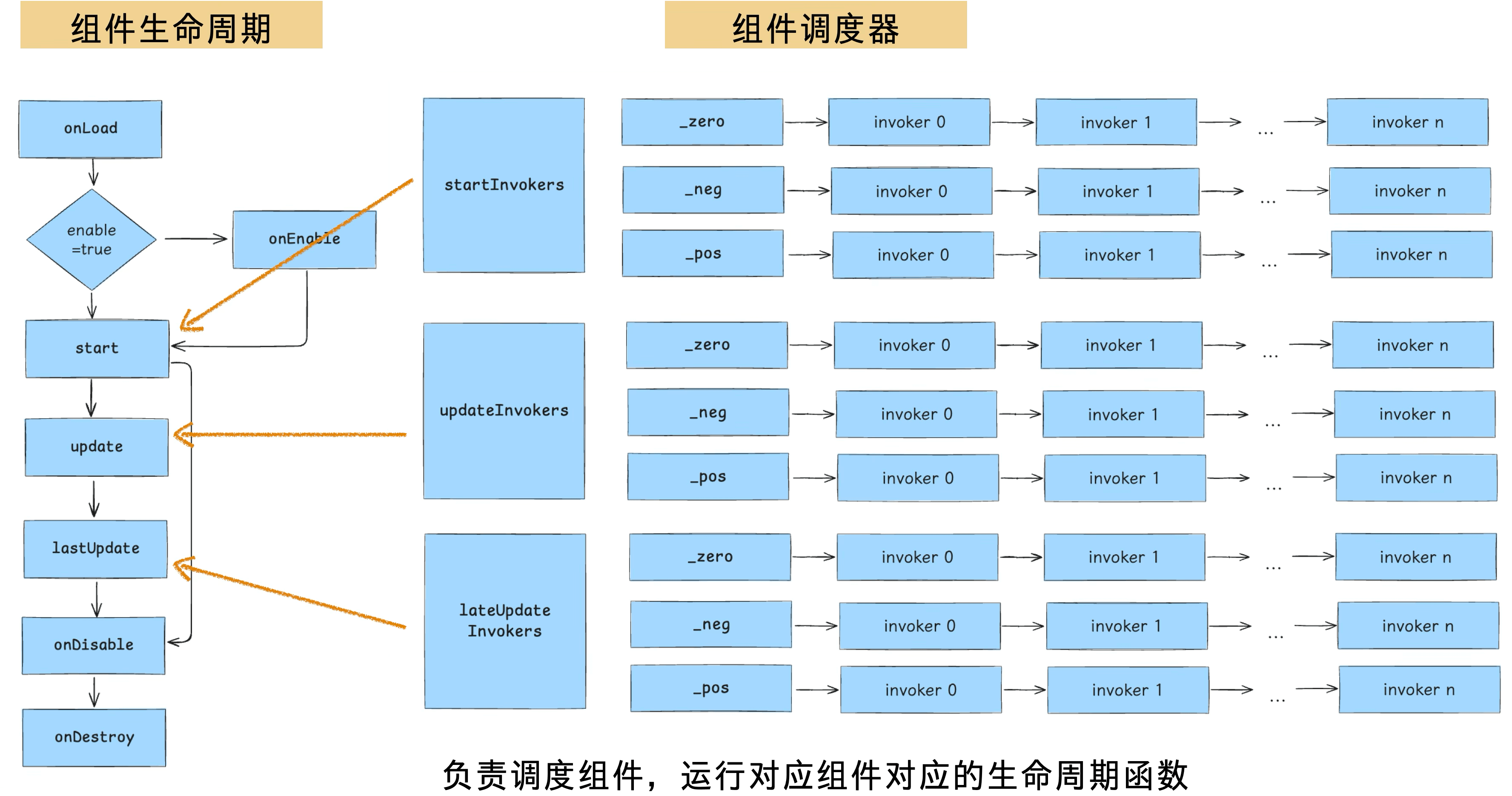
脚本资源加载执行后,游戏组件代码会进入到组件调度器中进行优先级调度。
Cocos 组件的生命周期如下图左所示,在 3 个关键的生命周期环境分别存在对应的调度器,每个调度器里设计了三个优先级队列,本质上每个队列的内容是由链表进行组织,顺序执行注册好的 invoker。
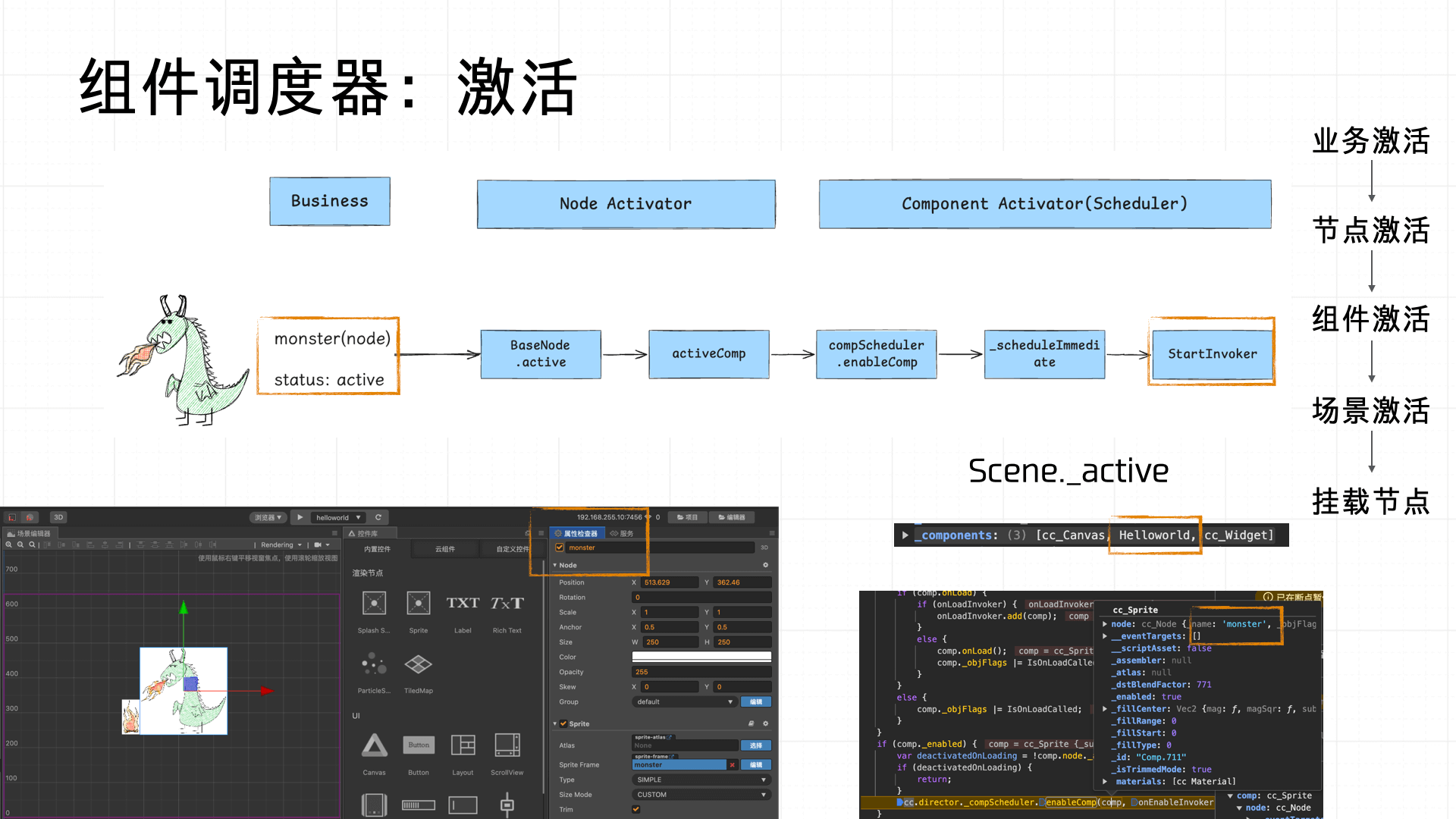
具体而言,从业务侧视角来看:在场景编辑器中创建节点(Node)时,业务方可以为其命名,并通过勾选“active”属性来决定该节点是否默认激活。一旦节点被标记为激活,加载阶段将由 Node Activator 负责激活该节点,接着 Component Activator(组件调度器的一部分)会依次激活该节点所挂载的各个组件,同时触发组件所在场景(Scene)的激活流程。最终,激活后的场景会将节点挂载入层级树,并完成组件 Invoker 的注册,交由调度器统一调度与管理。
整体流程如下图所示:
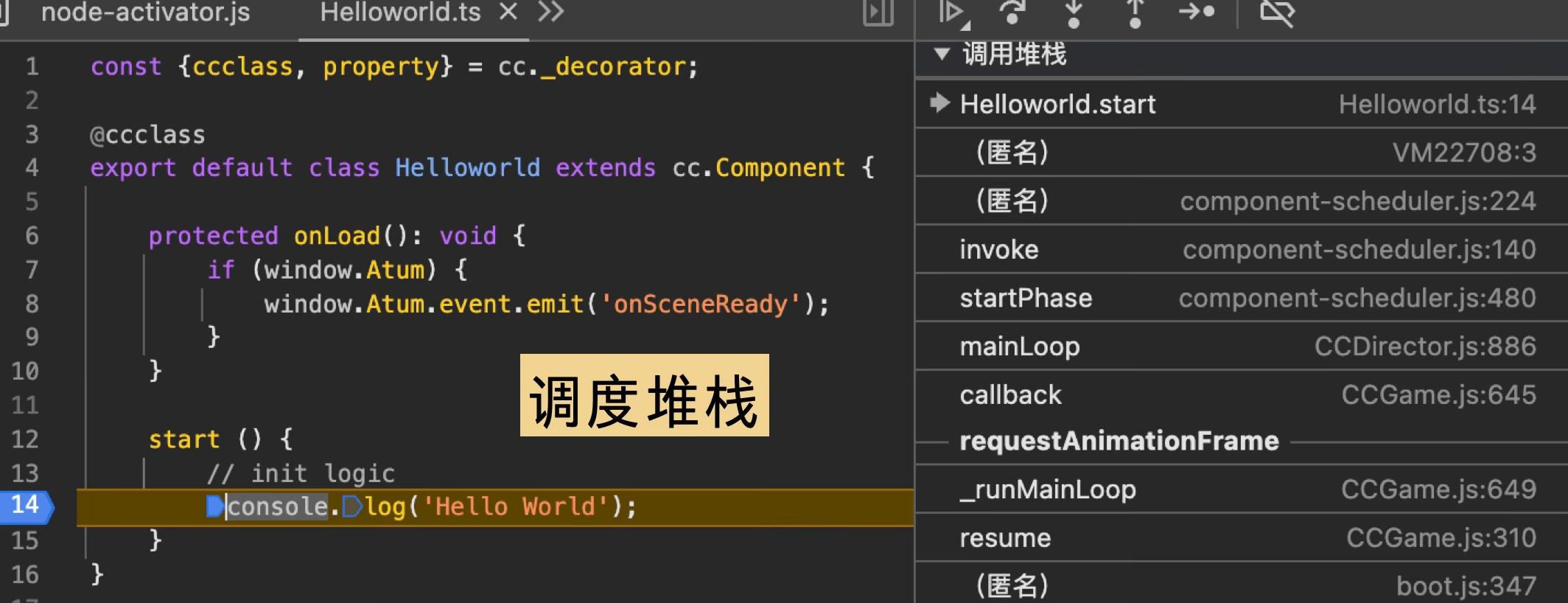
我们的 Demo 游戏组件的 start 生命周期下打印了一个 “Hello World”,调度堆栈如下所示:


3.3 Render Scene
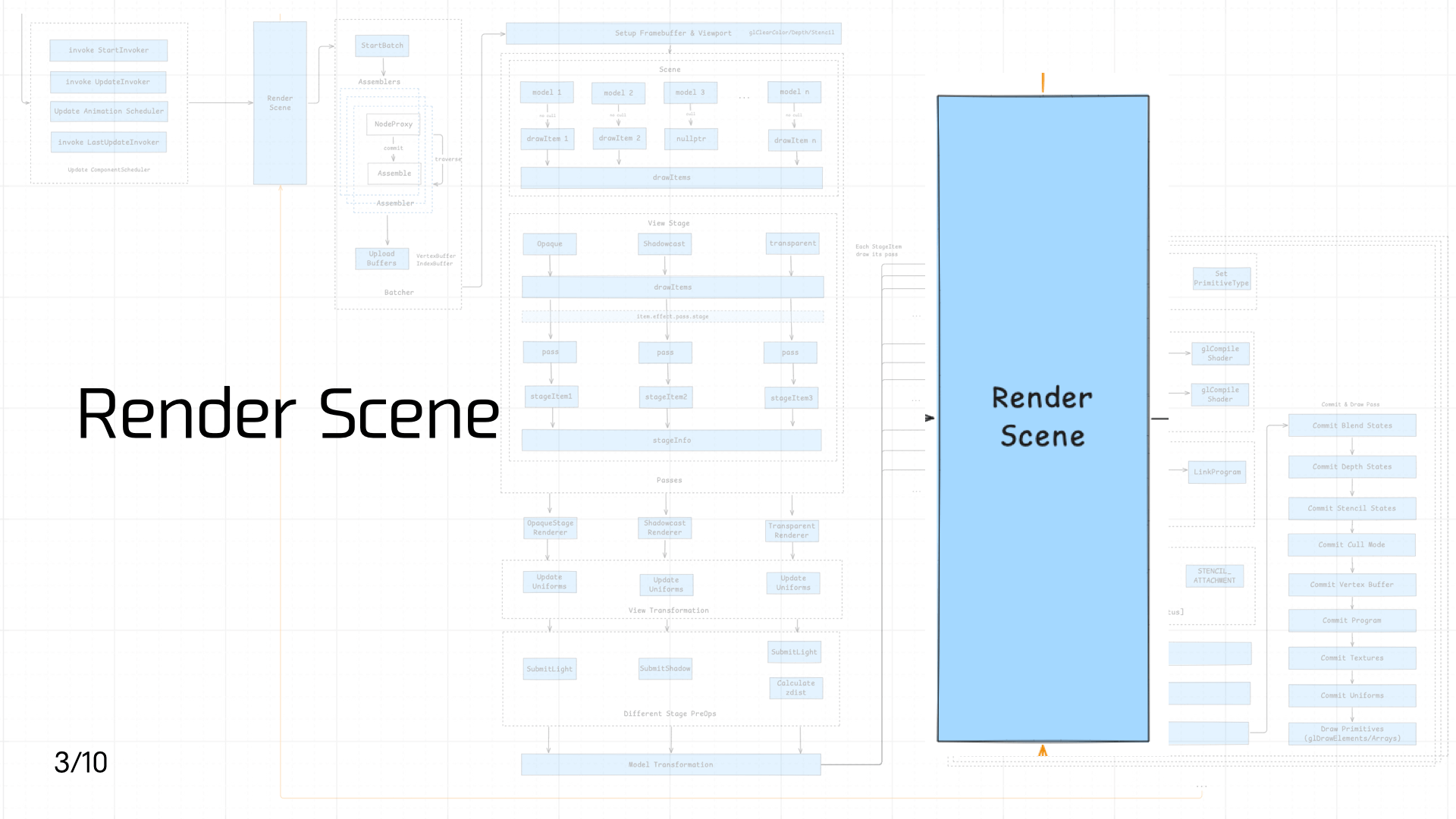
当场景激活并挂载了对应组件之后,接下来便是渲染场景,这一步就涉及到从 JS 调用到了 Native —— 即需要将 Scene 数据传递给 Native 侧,从而触发 Native 的 Render 流程。
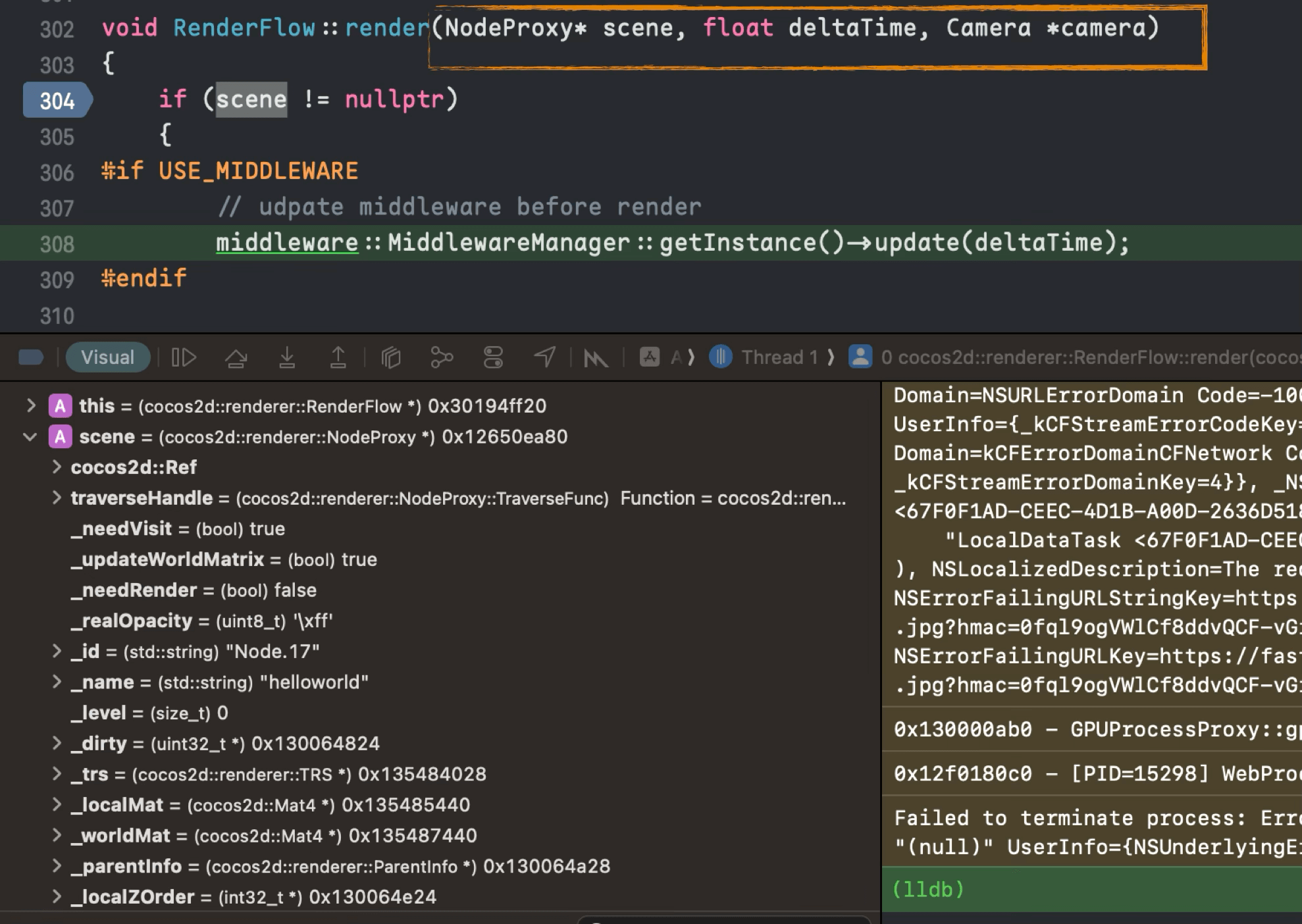
JS 和 Native 互相调用的方式有很多,适用场景也不同,这里也不展开说了。需要注意的是,在架构设计上,这里可以对 Binding 层做一层抽象,以便容器对接不同的 JS 引擎实现。
另外需要注意的是 Binding 要做好两端的 GC,因此 Binding 的实现上需要符合 RAII 原则:
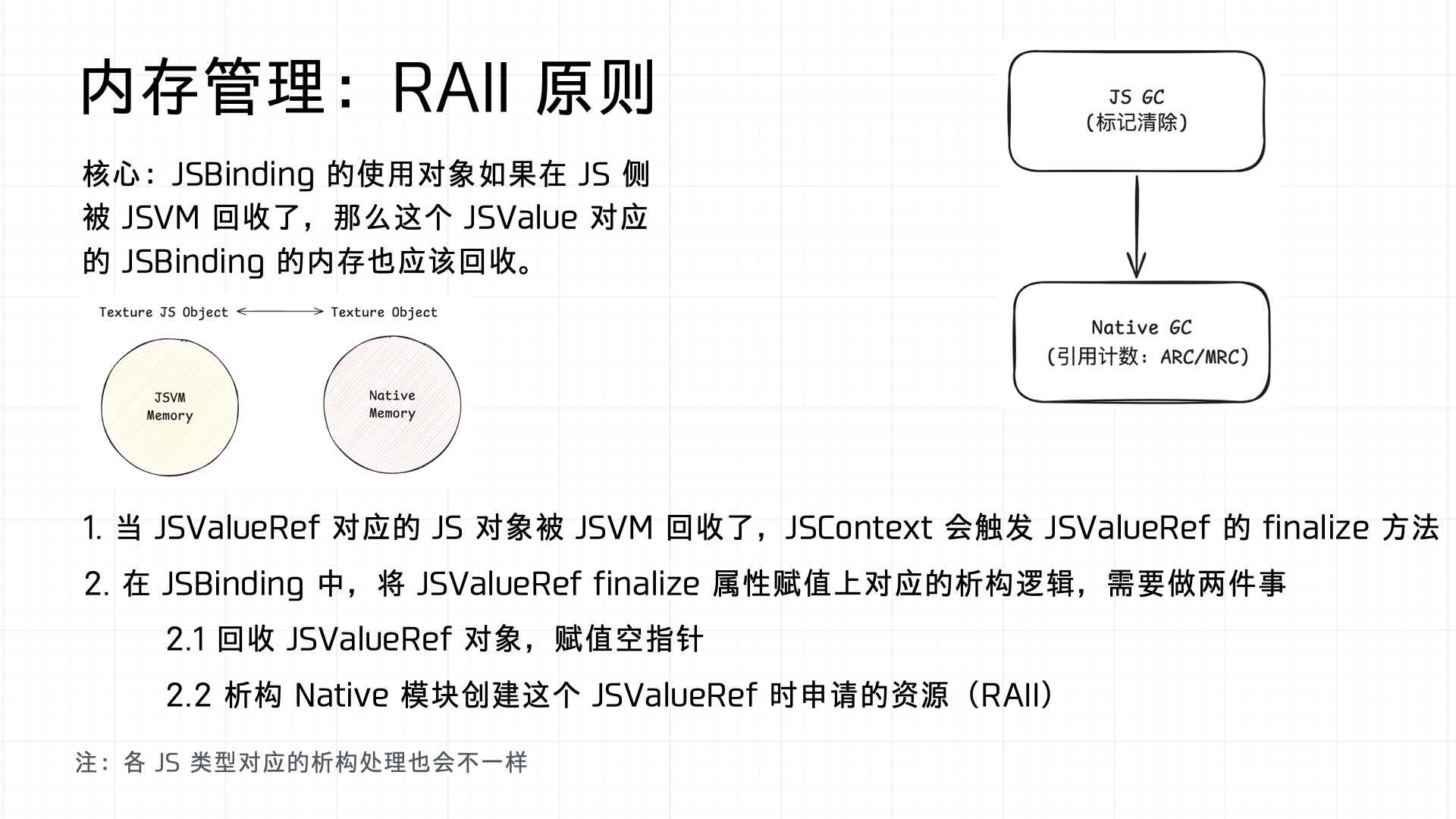
3.4 Batcher
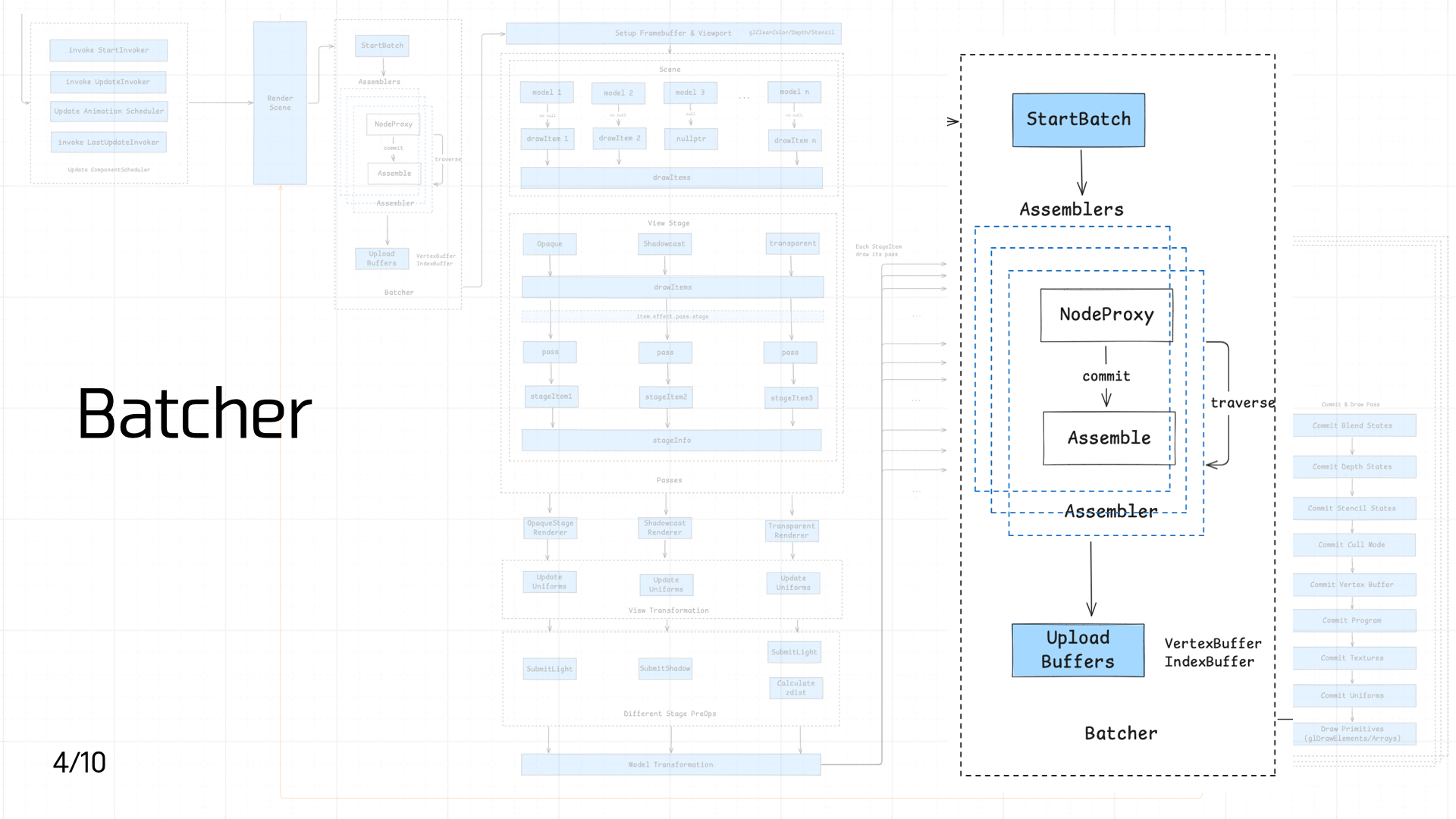
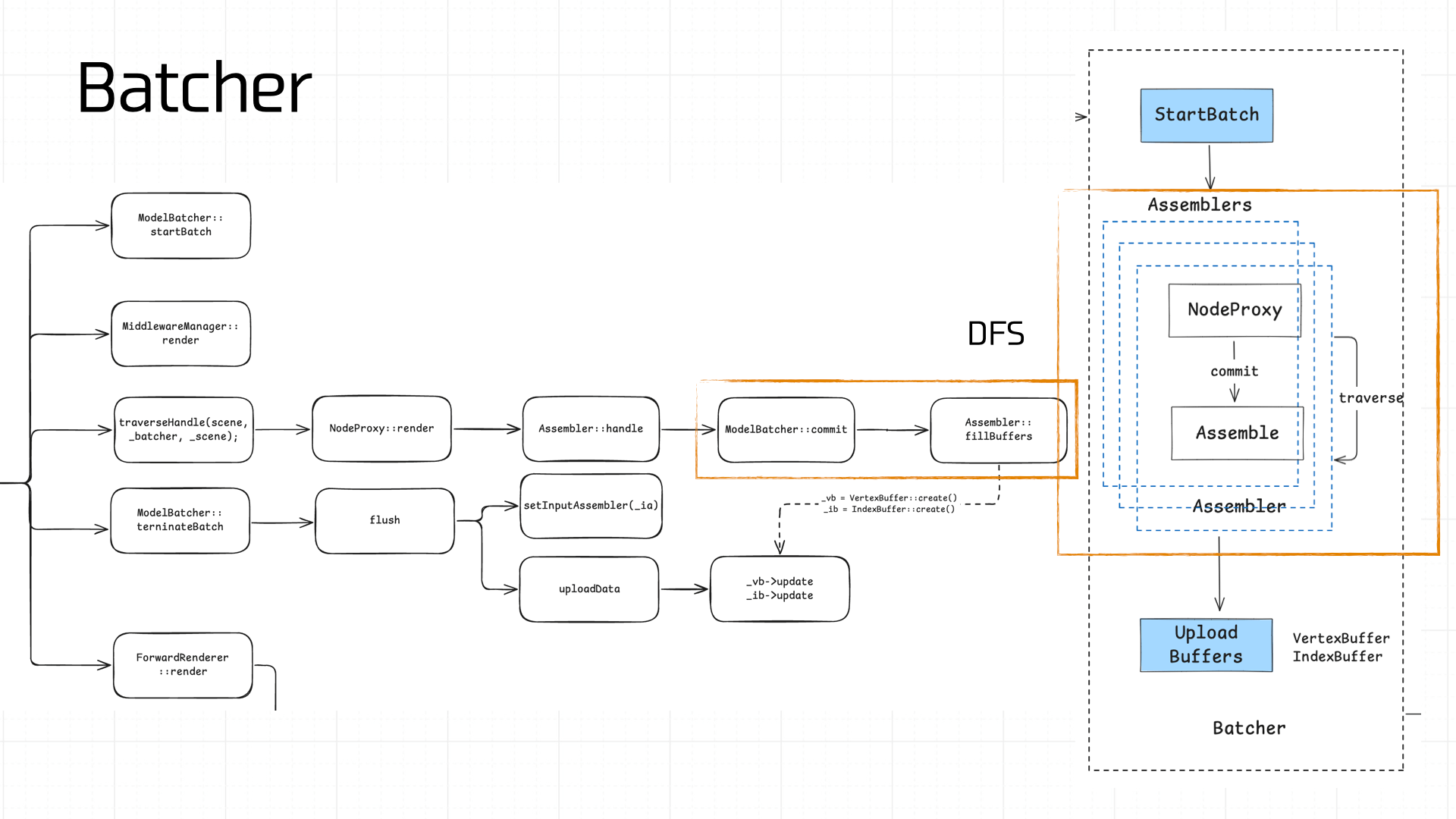
当 Native 拿到节点之后,便需要进行 Batch,这一步属于计算密集型,因此选择放在 Native 侧去做。
Batch 的流程比较复杂,核心思想是通过 DFS 对场景中的 Node 进行遍历,计算并装配(Assembler)顶点数据,得到顶点缓冲(VertexBuffer)和索引缓冲(IndexBuffer):
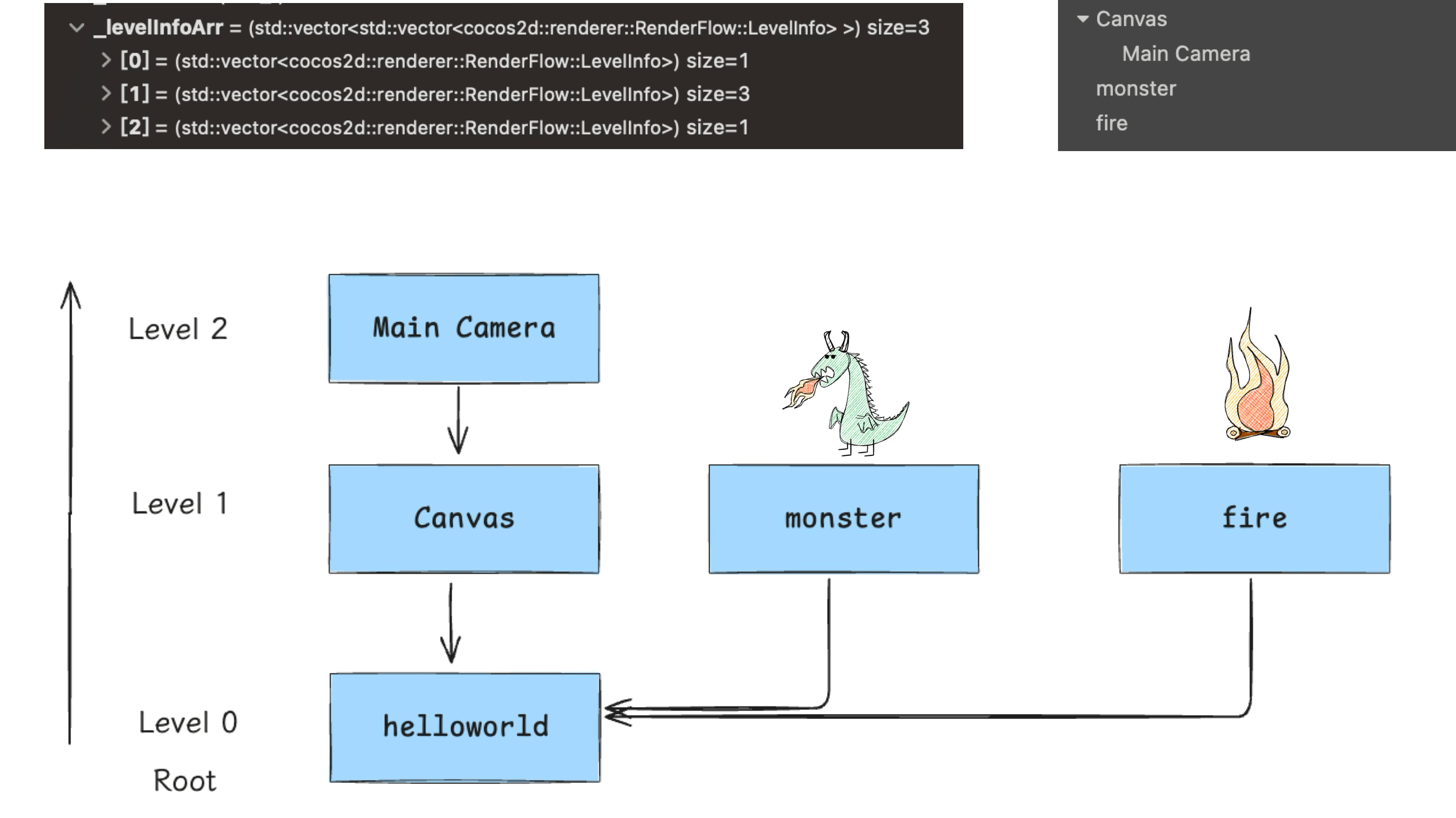
我们 Demo 游戏的场景树结构相对简单,遍历从 root 开始向下遍历(别忘了 Camera):
装配的计算流程比较复杂,下面仅对装配的结果做一个拆解,方便读者理解数据的由来。对于小恐龙而言,它是一个 Sprite2D,装备时会转成 Texture2D 处理,而后者在这个环节的核心,是需要拿到网格数据(Mesh Buffer)。下图是最后计算得到的 Mesh Buffer。
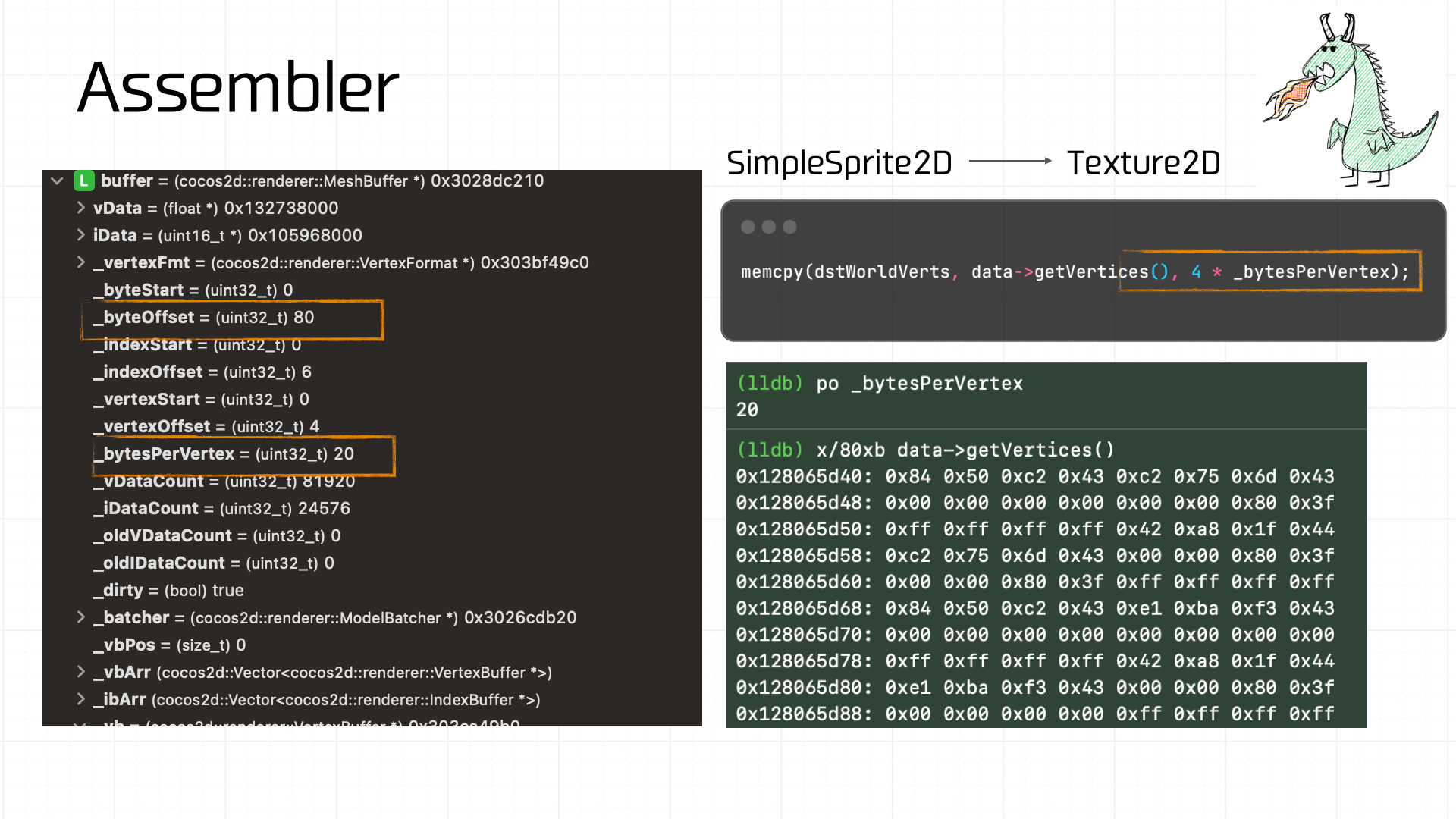
Mesh Buffer 由 Vertex Buffer 构成,这里装配的 Mesh Buffer,共 80 字节,其中每个顶点 20 字节,那么可以容易拆出 4 个 Vertex Buffer,同时根据 a_uv 的定义和偏移能拿到各自的 uv 坐标:
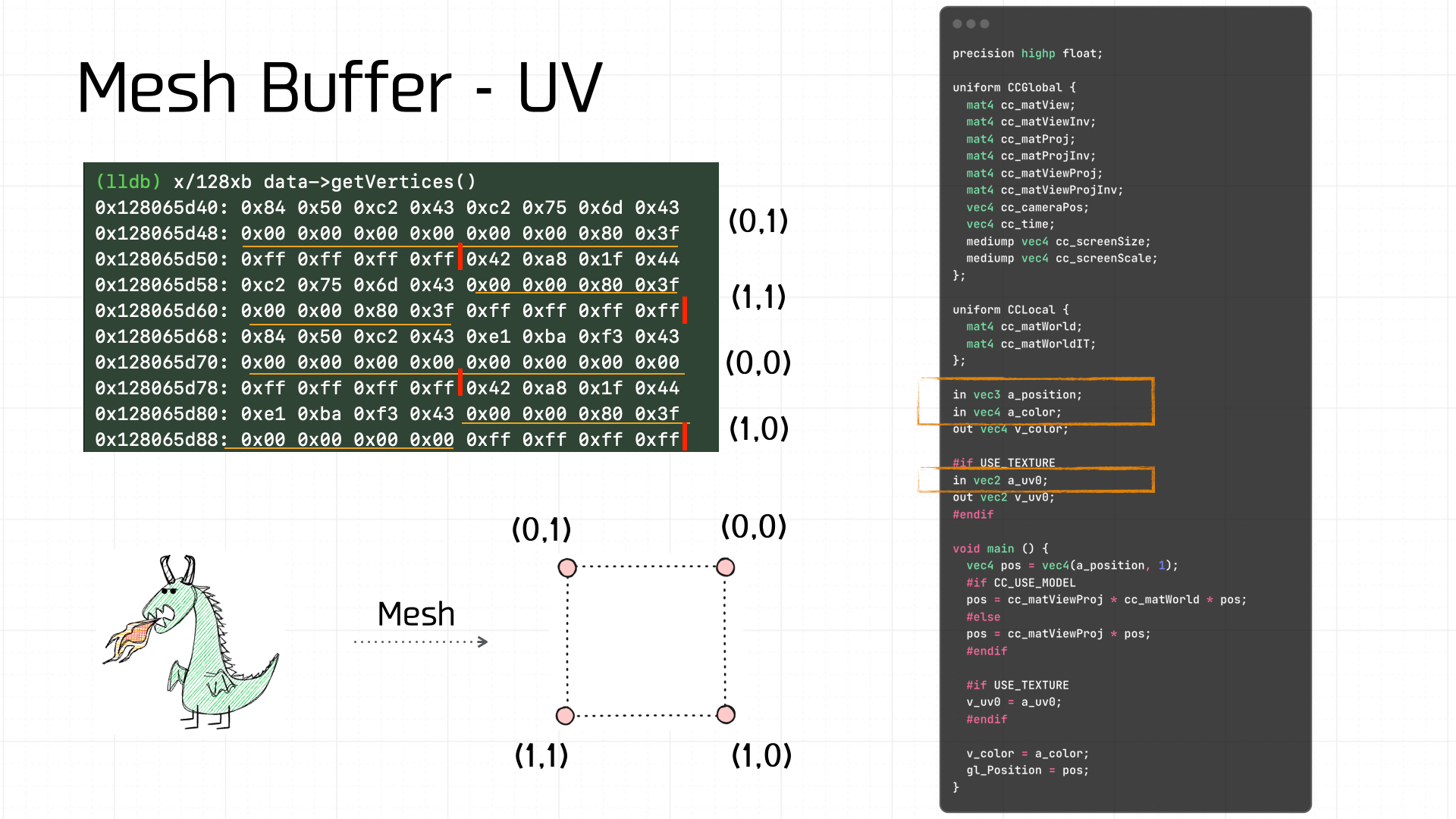
例如,根据顶点着色器的代码我们知道这个 Vertex Buffer 包括 3 部分数据:
a_position: 偏移量 0,8 字节。vec2,能算出来一个坐标。a_uv0: 偏移量 8,8 字节。vec2,就是 x,y,算出来之后是(0,1)。a_color: 偏移量 16,4 字节。vec4,RGBA,数值是 0xFFFFFFFF,即白色透明。

我们把四个顶点的坐标都算一下,可以拿到宽高和左上角的坐标,其实可以发现,这个数据就是业务侧在场景编辑器里对 Node 的宽高和坐标设置:

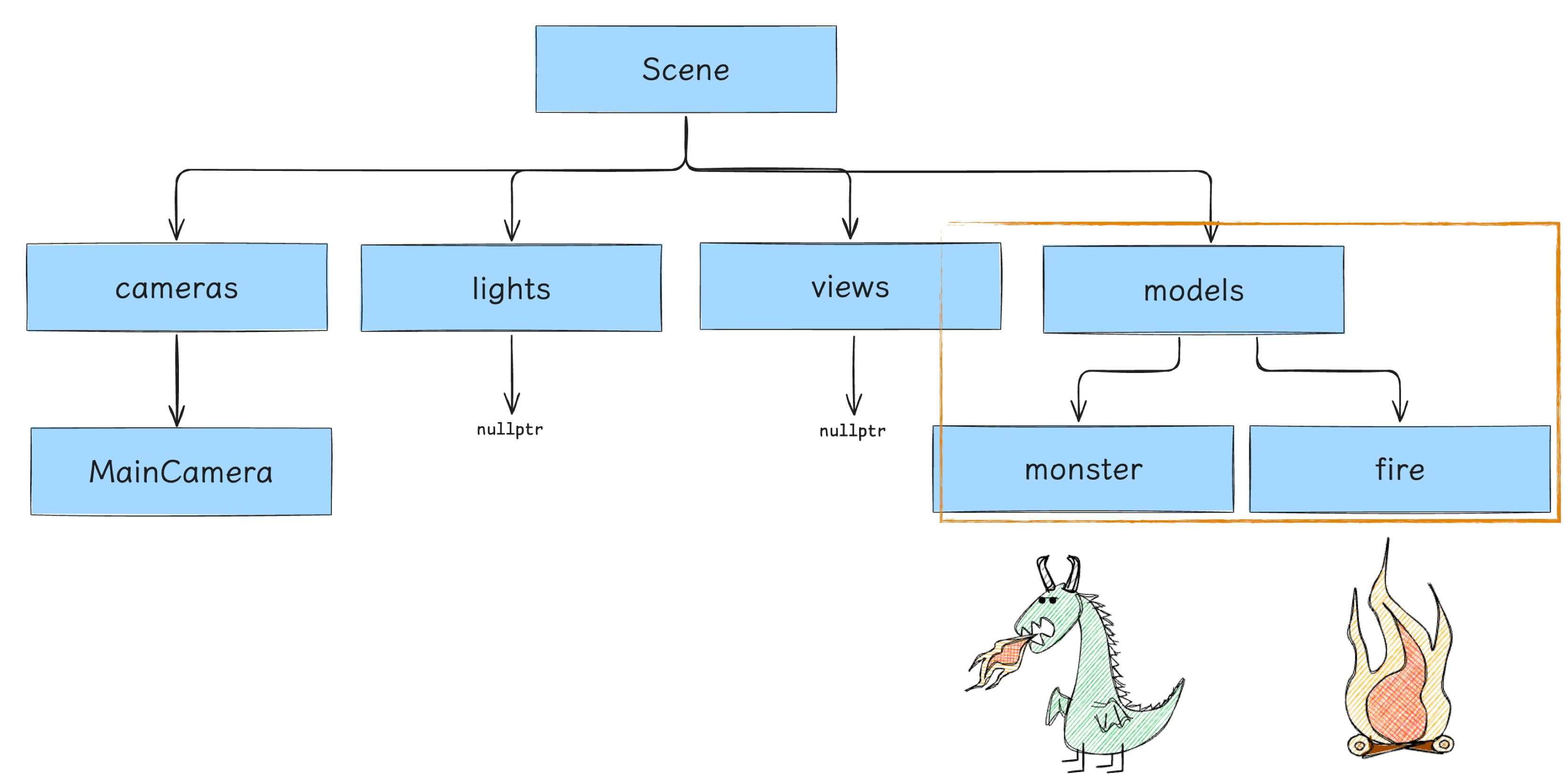
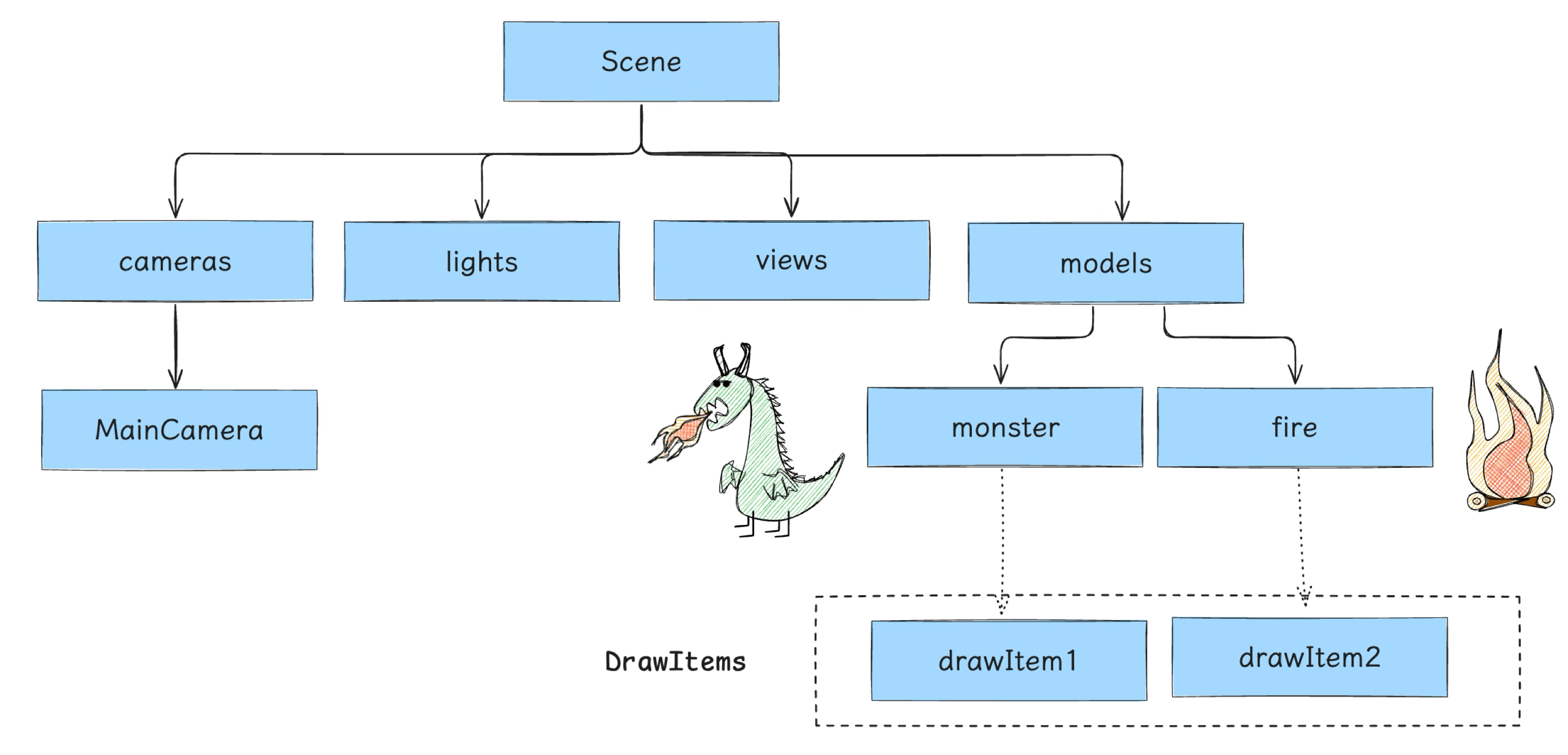
顶点装配完毕之后的 Node 会被放进 Models 里,最后做成 Scece Tree 中的 models 节点:
3.5 Setup
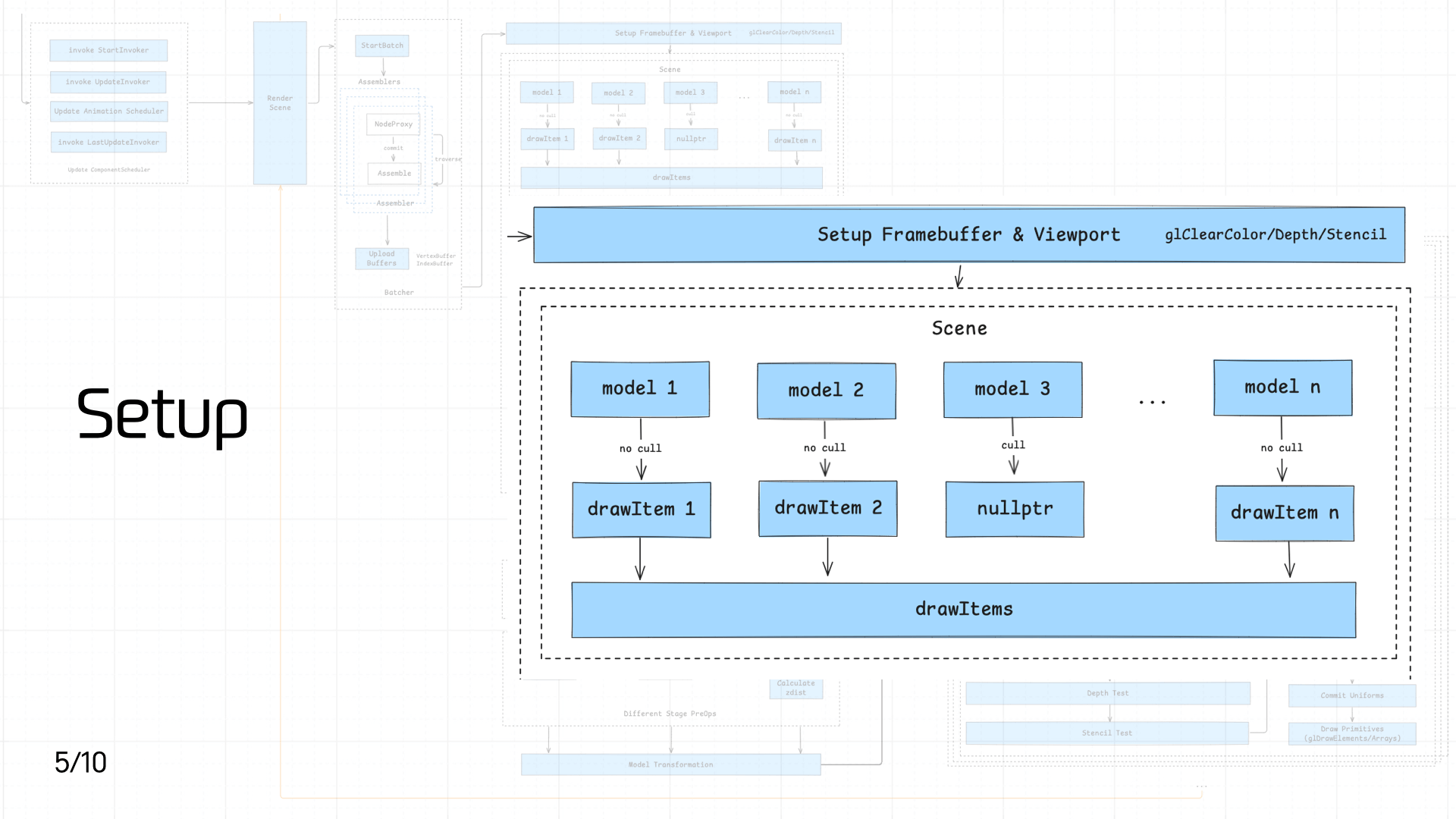
这个环节主要由两个逻辑组成:
- 设置 Framebuffer 和 Viewport
- 将 Scene 里的各个 Model 转成 drawItems 队列
首先是第一个部分,设置 Framebuffer 和 Viewport。具体而言,包括以下步骤:
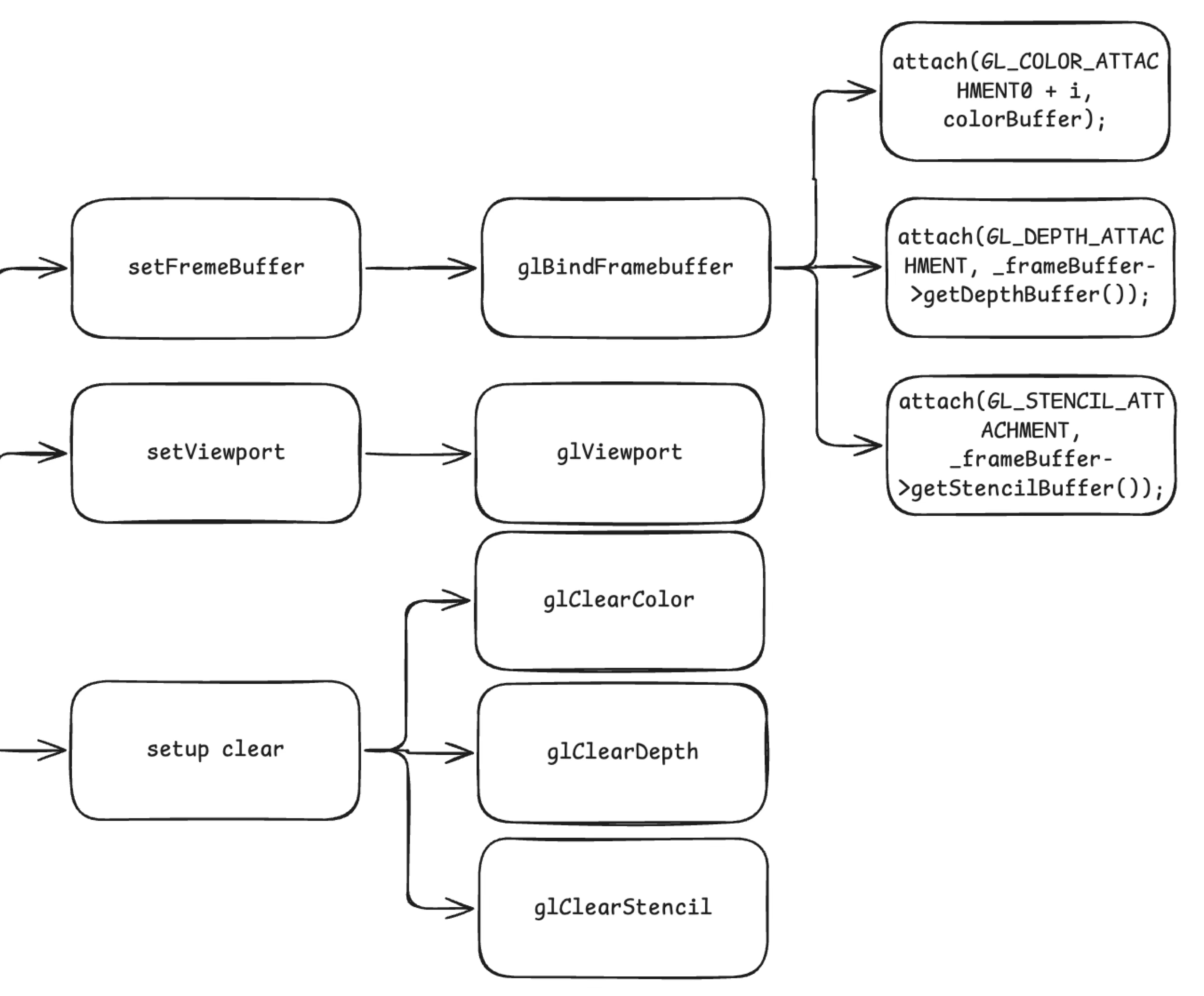
- 通过
setFrameBuffer函数调用glBindFramebuffer绑定 Framebuffer 帧缓冲对象,并分别附加颜色缓冲(COLOR_ATTACHMENT,存储渲染的颜色信息)、深度缓冲(DEPTH_ATTACHMENT,存储每个像素的深度信息,用于深度测试)和模板缓冲(STENCIL_ATTACHMENT,存储模板测试的结果),确保后续绘制有正确的渲染目标。 setViewport调用glViewport设置视口,决定最终渲染区域在屏幕上的映射范围setup clear依次执行glClearColor、glClearDepth和glClearStencil,初始化颜色、深度和模板缓冲的清除值,为每一帧绘制提供干净的初始状态。
unsigned int fbo;
glGenFramebuffers(1, &fbo);
接下来,游戏引擎会将 Scene 里的各个 Model 转成一对一的 DrawItem,一个 DrawItem 的数据结构如下所示:

最后,引擎将这些 DrawItem 组装成 DrawItems 队列,以便后续流程处理。
3.6 Render Stage
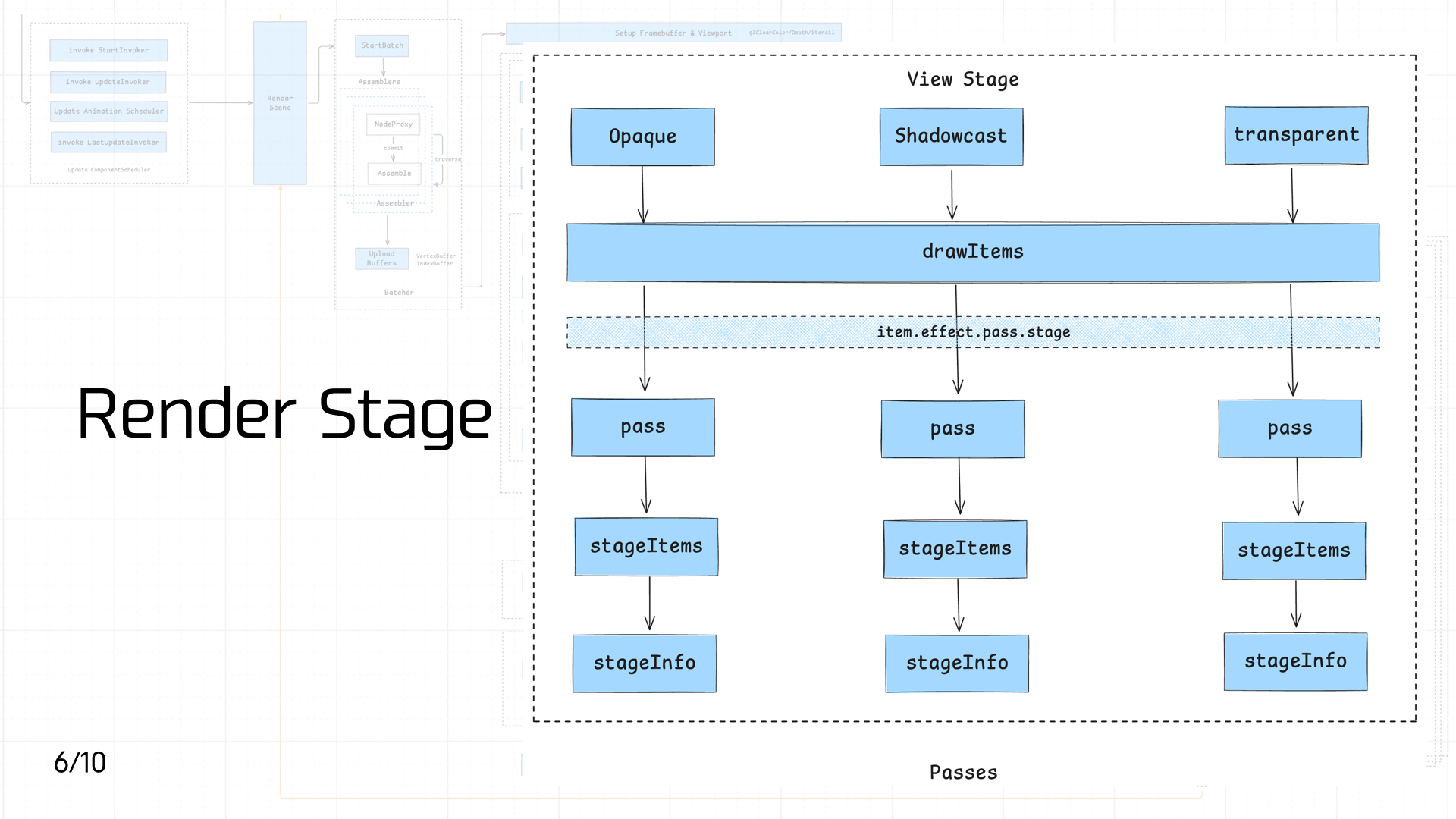
接下来进入 Render Stage 阶段,渲染管线会开始对 DrawItems 进行分类处理。根据渲染的 Material 的需求,DrawItems 会被分发至三个不同的 Pass,分别对应 Opaque、Shadowcast 和 Transparent 三个阶段,关系到材质属性和阴影投射:
- Opaque:用于绘制完全遮挡光线的物体,如墙面、地板、角色模型等。这类物体会首先渲染,通过深度缓冲区(Z-Buffer)完成遮挡剔除,避免后续无效绘制,提升渲染效率。
- Shadowcast:专门处理场景中的阴影投射。此阶段会根据光源信息,对具有投影能力的物体进行阴影绘制,为场景添加真实感与空间深度,尤其适用于强光源或需要表现光影效果的环境。
- Transparent:负责绘制允许光线穿透的半透明物体,如玻璃、水面、特效粒子等。透明物体通常需要根据视角进行深度排序,以保证前后层次正确渲染,避免视觉穿插错误。
通过将 DrawItems 按照物体特性分发至不同 Pass,渲染管线能够有针对性地对 Effect 进行实现。
业务侧可以在代码里创建一个指定的 Material,之后管线就会走到对应的 pass 进行处理:
// 创建一个立方体网格
const cube = new cc.MeshRenderer();
cube.mesh = cc.GizmoMesh.createBox(1, 1, 1);
// 设置材质为不透明
const opaqueMaterial = cc.Material.create();
opaqueMaterial.initialize({
effectName: 'builtin-unlit',
technique: 'opaque',
});
cube.setMaterial(opaqueMaterial, 0);
因为我们 Demo 较为简单,因此最后生成的 StageInfo 只包含 Opaque Pass:
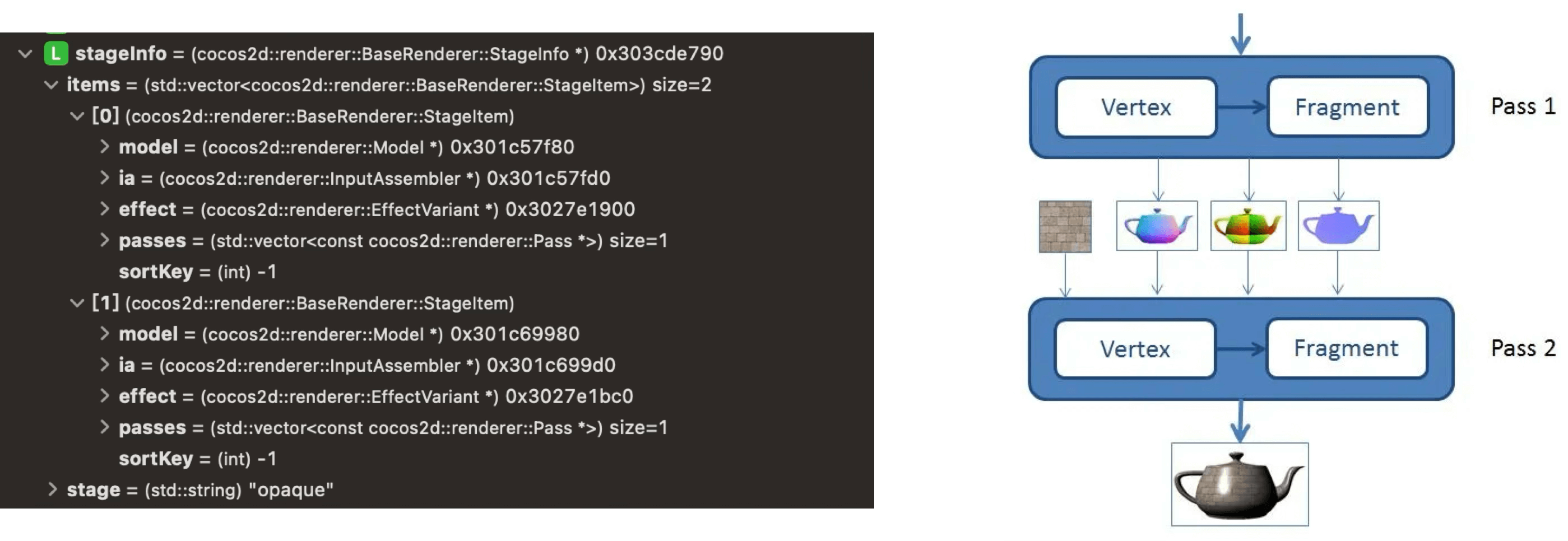
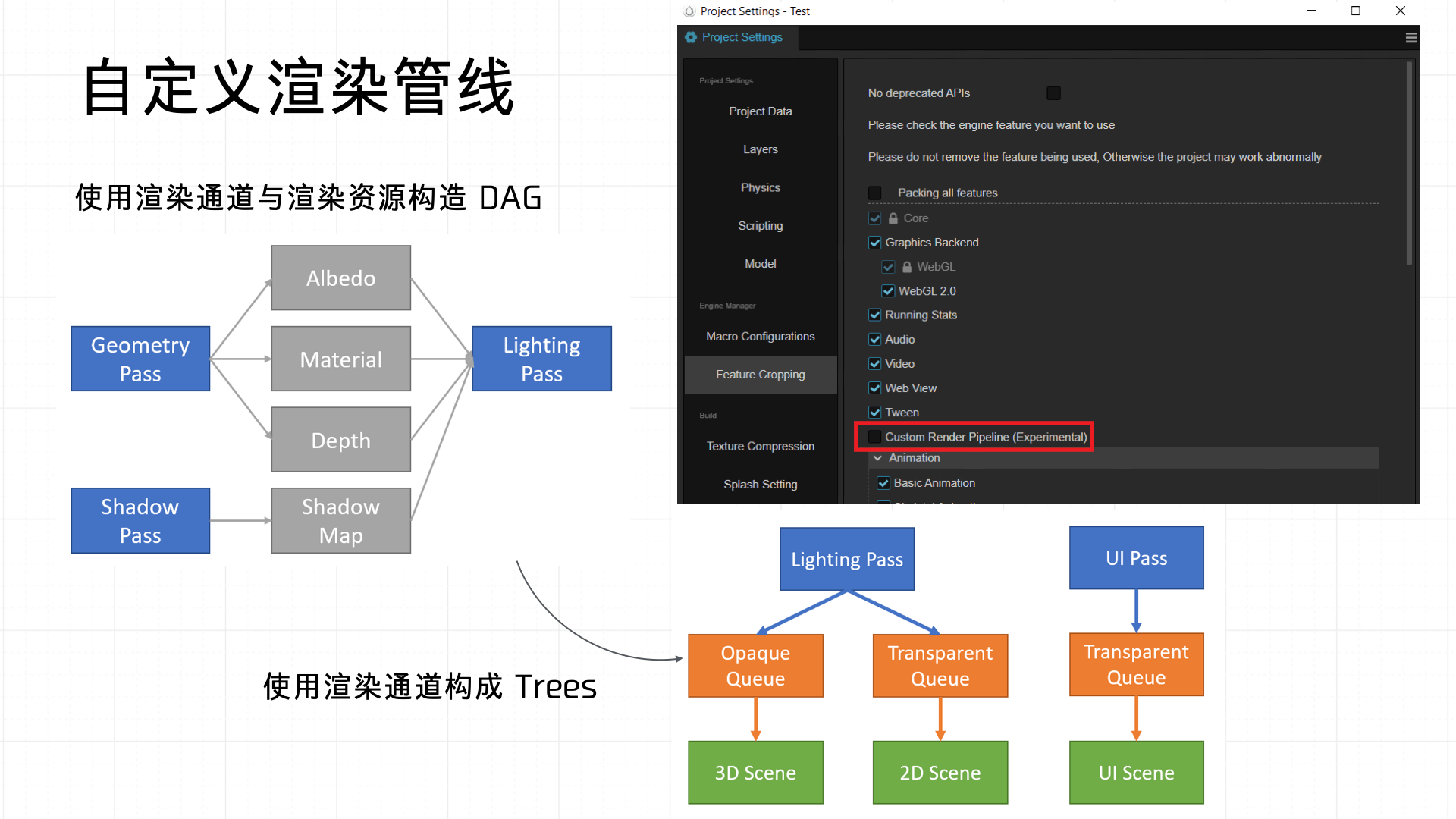
当然,在 Cocos 中也是支持自定义渲染管线,实际上就是自定义这个环节的 Passes,定义完之后可以直接应用在 Opaque、Shadowcast 和 Transparent 三个阶段之上:
3.7 ModelView Transformation
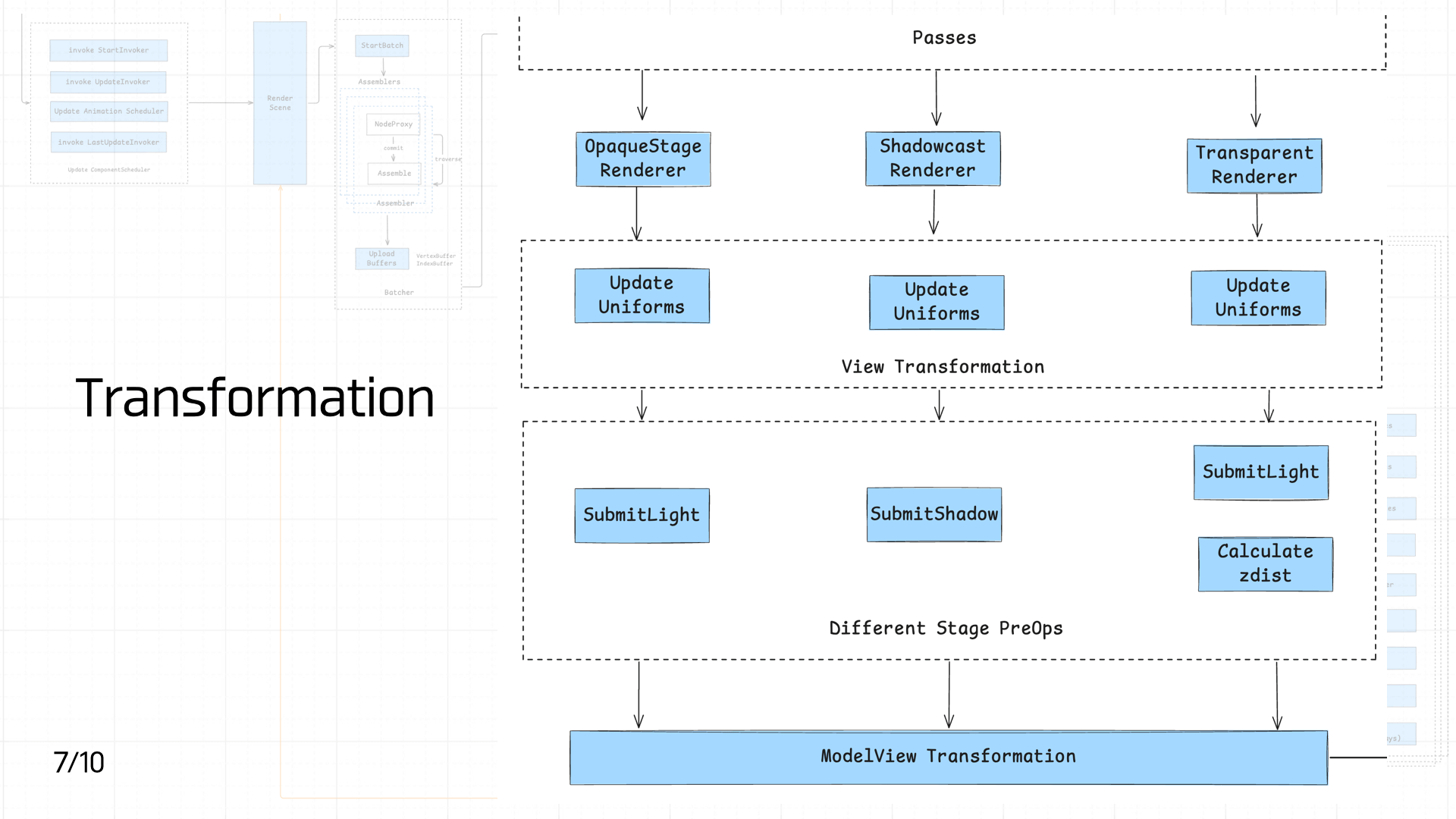
经过 Passes 之后,场景中的 DrawItems 会根据其属性被分别送入 OpaqueStage Renderer、Shadowcast Renderer 和 Transparent Renderer 进行初步处理。各个 Renderer 在此阶段主要负责更新与视图相关的 Uniforms(如矩阵、材质参数等),以确保后续渲染过程中所需的视角、空间信息正确。这一部分可归类为 View Transformation 阶段,统一完成视图坐标系下的变换数据准备。
紧接着不同的渲染阶段会有差异化的预处理操作:不透明物体和透明物体会分别执行 SubmitLight 以提交光照信息,而投影阶段则专门进行 SubmitShadow 以生成阴影数据。同时,透明阶段由于涉及深度排序问题,还会额外执行 Calculate zdist 以计算对象的深度信息。
所有这些预处理完成之后,最终将统一进入 ModelView Transformation 阶段,得到视图投影矩阵,从而完成从模型空间到屏幕空间的最终变换,以便于后续的图元栅格化与像素着色工作。
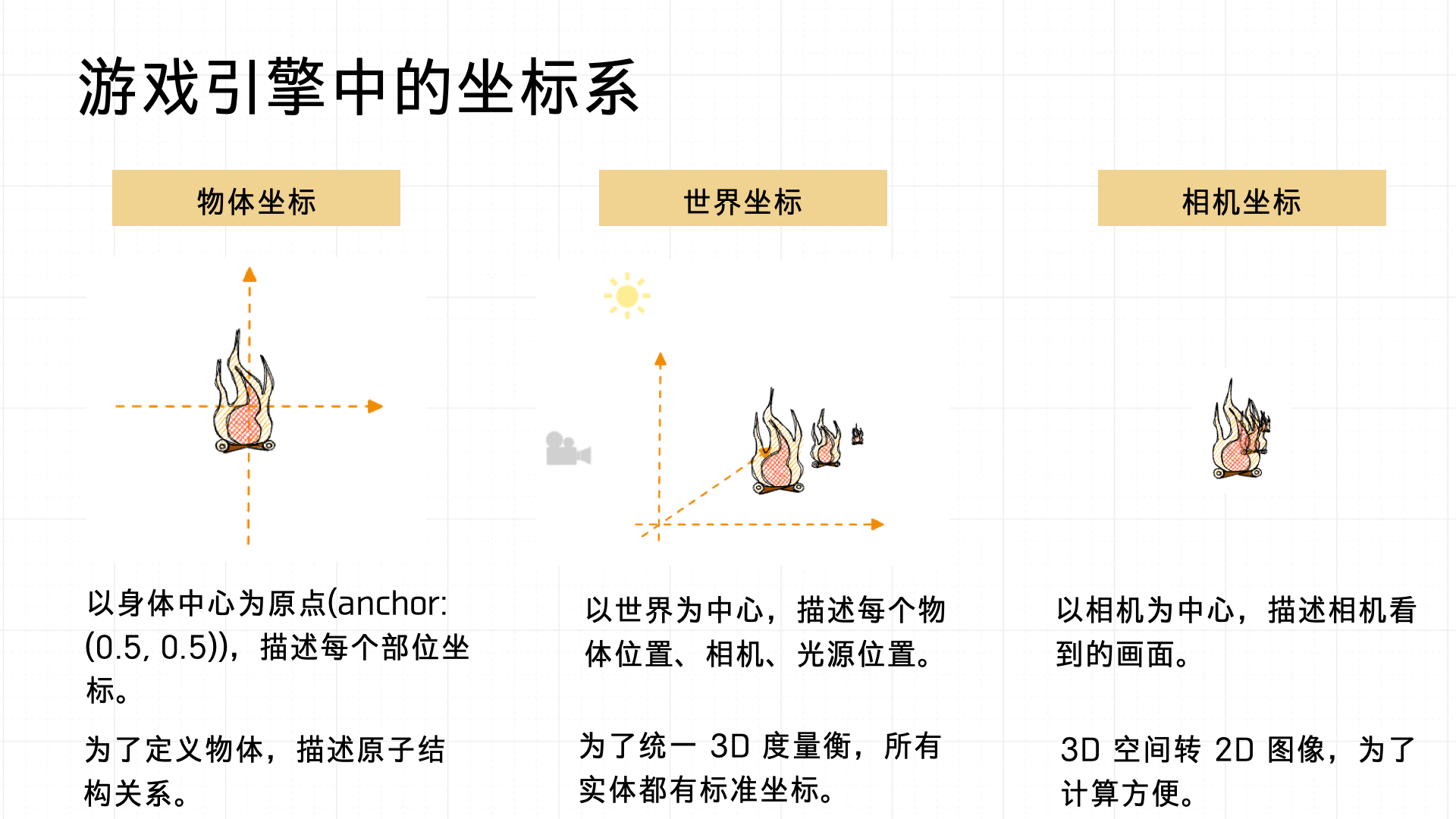
在讲解 ModelView Transformation 之前,先来介绍下游戏系统中的坐标系统的定义。一般会涉及物体坐标、世界坐标与相机坐标三种主要坐标系。
- 物体坐标系:以物体自身的中心点(anchor 通常设置为(0.5, 0.5))为原点,用于描述物体内部各个部位的位置关系,便于定义复杂物体内部的原子结构关系。
- 世界坐标系:则是以整个场景的中心作为原点,用来统一描述场景内所有物体、相机以及光源的位置关系,确保场景整体的空间一致性。
- 相机坐标系:以相机的位置作为原点,是为了将 3D 空间转化为 2D 图像,以便进行计算和渲染。
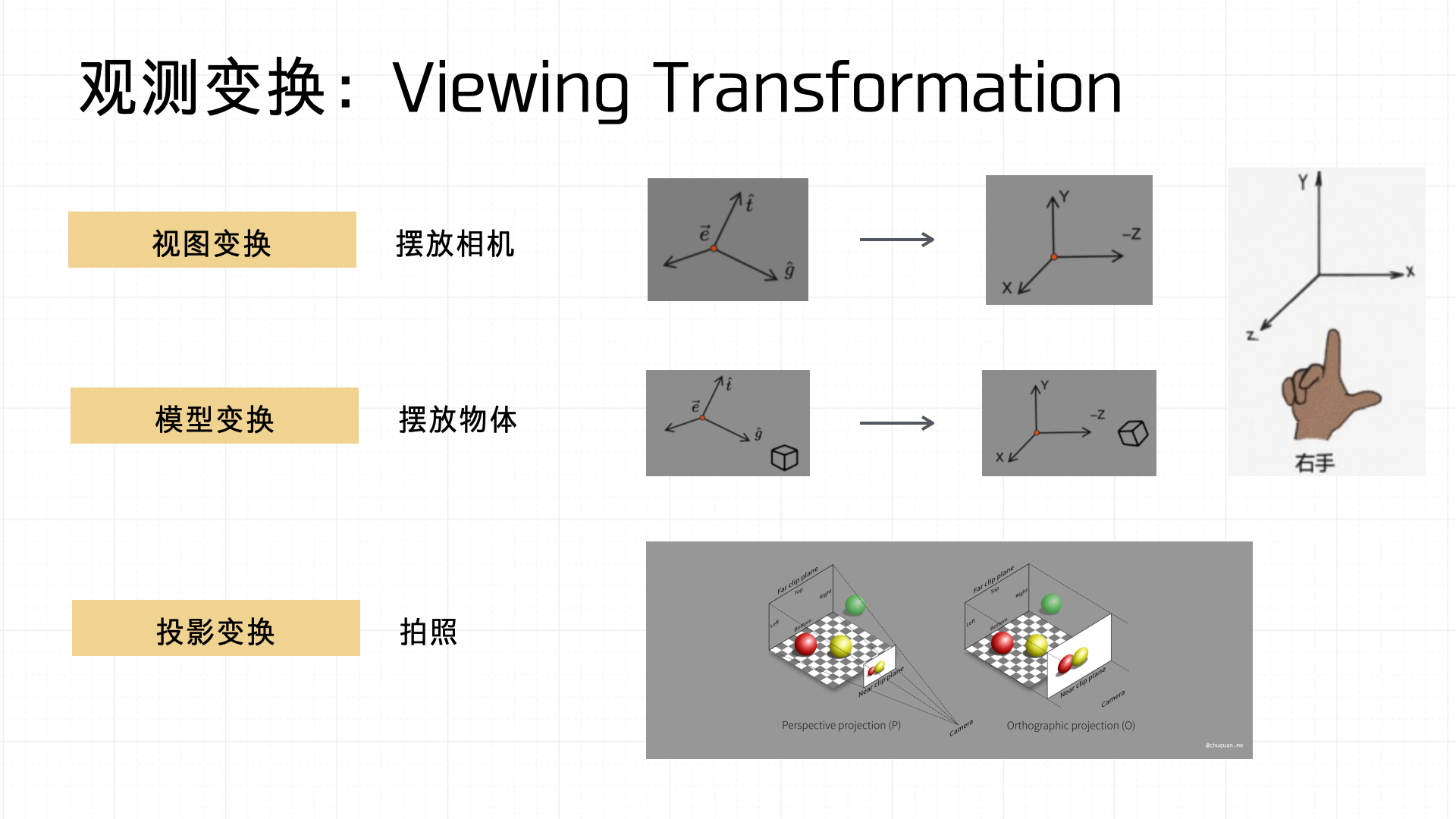
基于这套坐标系统下,观测变换(Viewing Transformation)主要包括视图变换、模型变换与投影变换三个步骤。
- 视图变换:可看作是将相机放置到场景中的过程,主要是定义相机的朝向和位置。
- 模型变换:对物体进行放置或调整位置、旋转以及缩放等操作。
- 投影变换:类似于摄影,通过投影方式,将三维物体的信息映射到二维的屏幕空间。
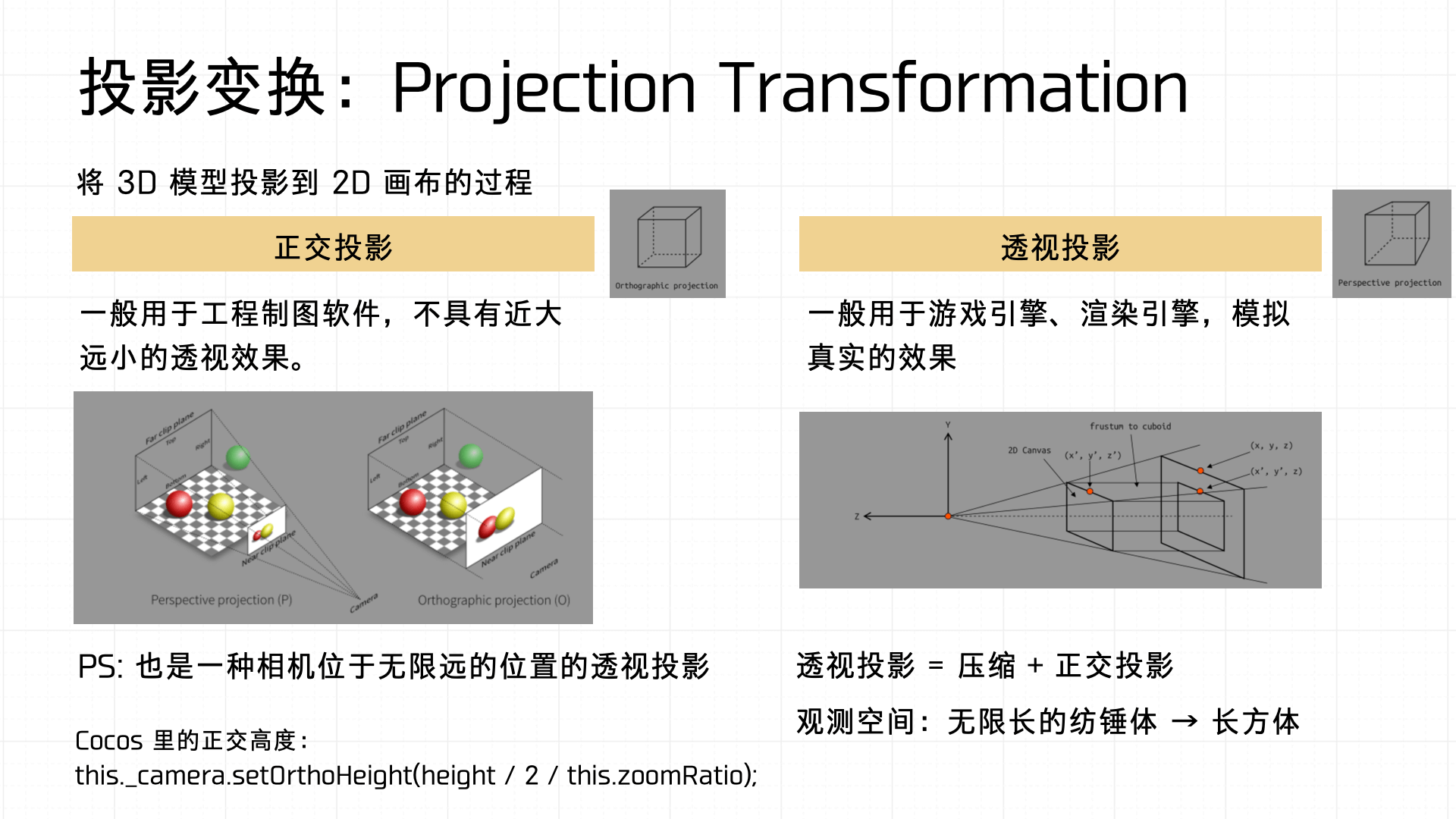
下面重点说说投影变换(Projection Transformation),它分为正交投影(Orthographic Projection)与透视投影(Perspective Projection)两种方式。
- 正交投影常用于工程制图软件,不体现远近透视效果;
- 透视投影广泛应用于游戏、渲染引擎中,能更真实地模拟人眼观察到的空间透视效果。
而透视投影的数学本质是压缩加上正交投影的结合,实际将一个无限延伸的观察空间(视锥体)转化为一个便于计算的立方体。
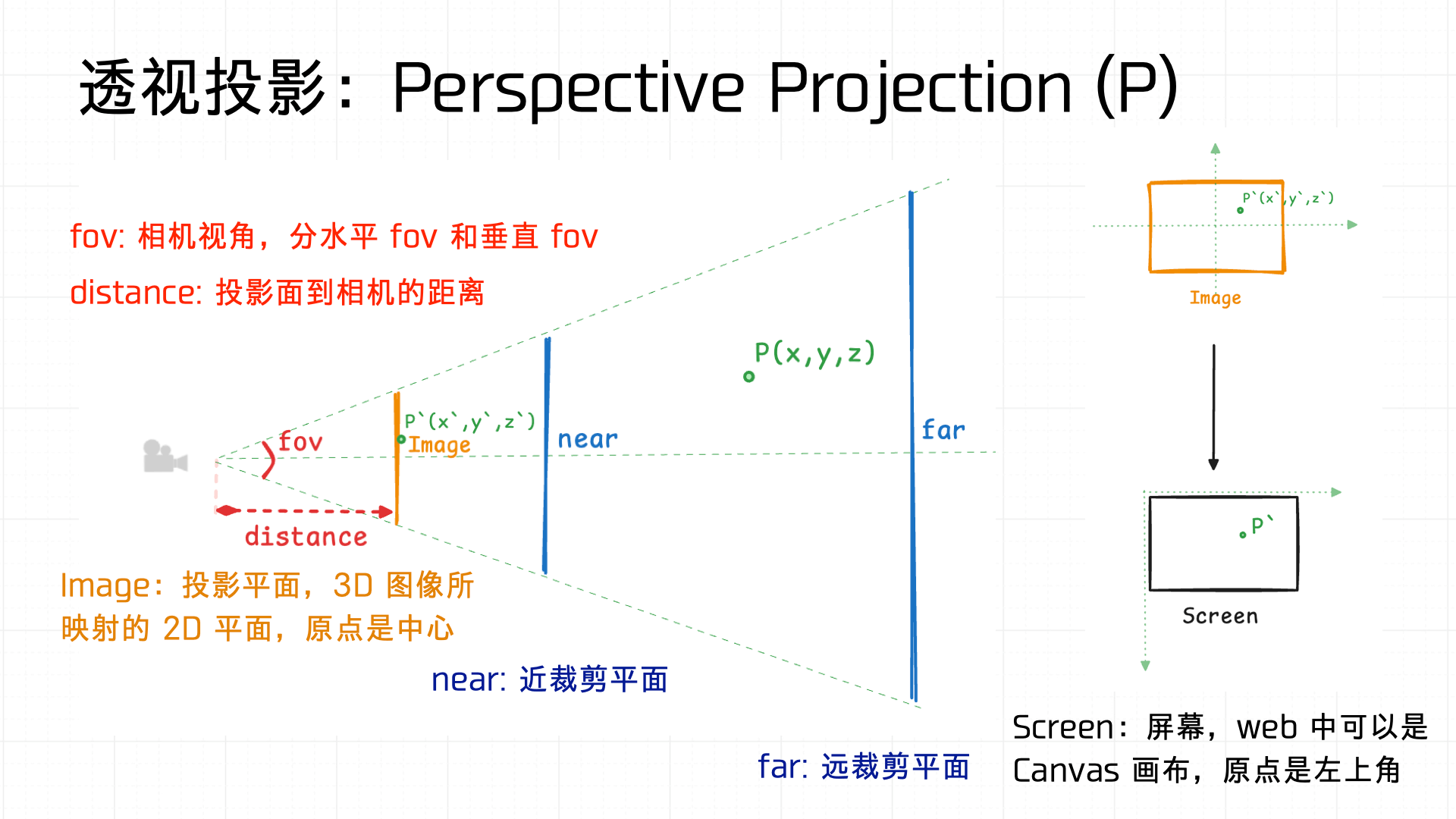
这里简单画了个图来介绍透视变换的实现,fov(视角)定义相机的视场宽度,可以分为水平fov与垂直 fov;distance 定义投影平面与相机之间的距离。视景空间通过近裁剪平面(near)和远裁剪平面(far)定义渲染的范围,通过相似三角形的计算,最终将 3D 空间映射到 2D 屏幕(Canvas)。
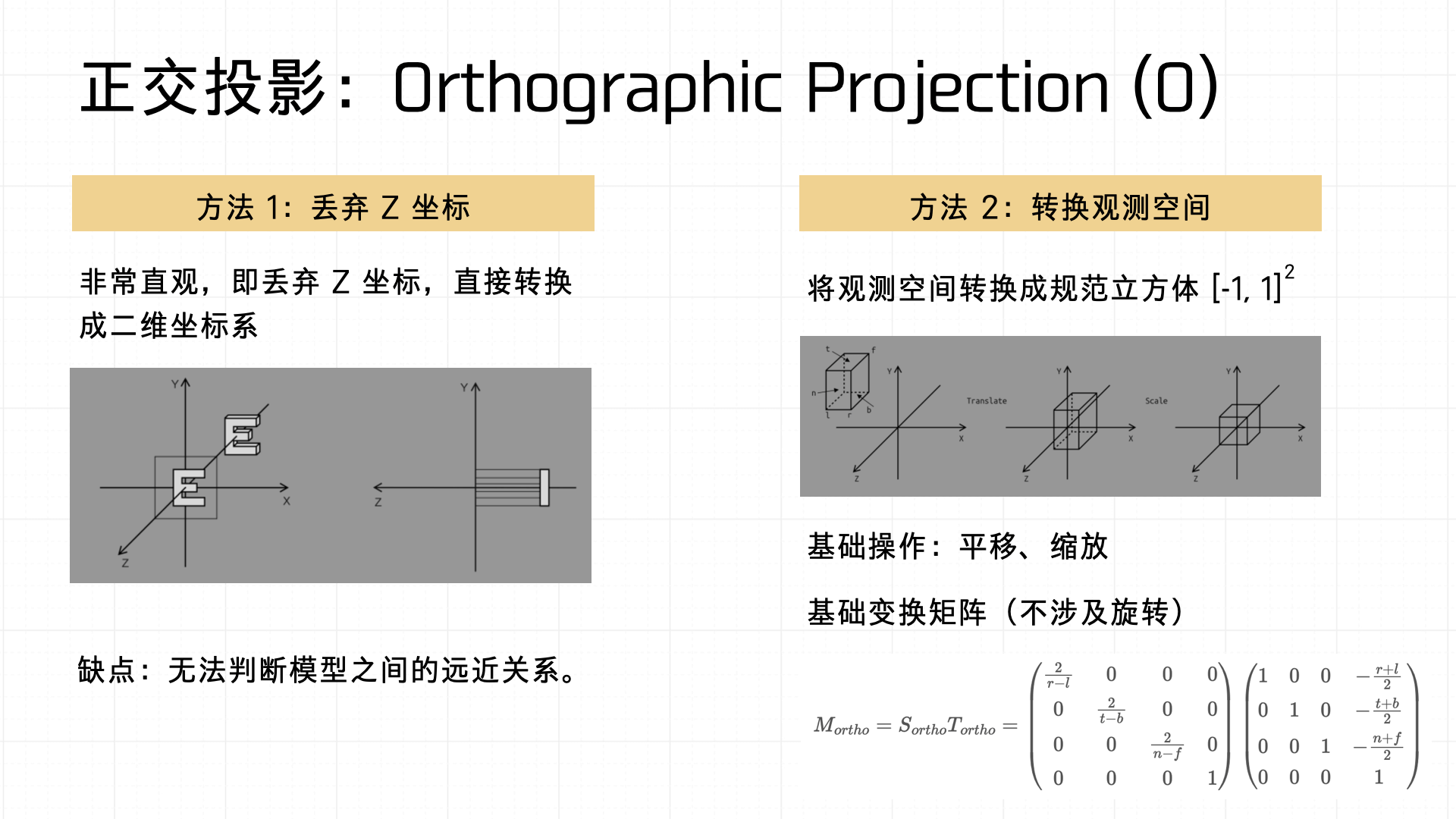
说完了透视投影,我们再看看投影变换的另一种方式——正交投影。其通常有实现的方式有两种:
- 直接舍弃Z坐标,将 3D 物体转化为 2D 物体,直观但无法表现空间深度;
- 将观察空间变换成标准的立方体后,利用变换矩阵进行计算。
综上,坐标转换流程具体包括物体坐标到世界坐标,再到相机坐标,接着到投影坐标,最终映射到屏幕坐标。
- 首先,在编辑器中定义坐标相加的关系,将物体放置到场景中;
- 之后,通过视图变换调整相机位置、模型变换调整物体位置;
- 再经过投影变换将 3D 空间投射到 2D 空间;
- 最后进行坐标系转换,确保渲染到正确的屏幕位置。

在这个过程中,会计算得到视图矩阵(View Matrix)、投影矩阵(Projection Matrix),最终矩阵相乘拿到视图投影矩阵(Model-View-Projection Matrix)。我们结合 Demo 游戏的断点数据,分别看看他们仨是怎么计算得到的。
首先是视图矩阵,它负责将世界坐标系转化为相机坐标系,其中包含坐标轴的缩放和平移操作。实际计算中,通常涉及坐标轴补齐,即齐次坐标的补齐过程,确保矩阵运算的有效性。

之后是计算投影矩阵,它用于将相机空间进一步映射到标准化的设备空间(Normalized Device Coordinates, NDC),矩阵中的缩放系数根据屏幕的宽高比和设定的正交高度来计算。

最终的渲染过程通常使用视图投影矩阵(Model-View-Projection Matrix, MVP)。视图投影矩阵是视图矩阵与投影矩阵的组合,用于最终的顶点变换和着色器渲染计算。

3.8 Link Program
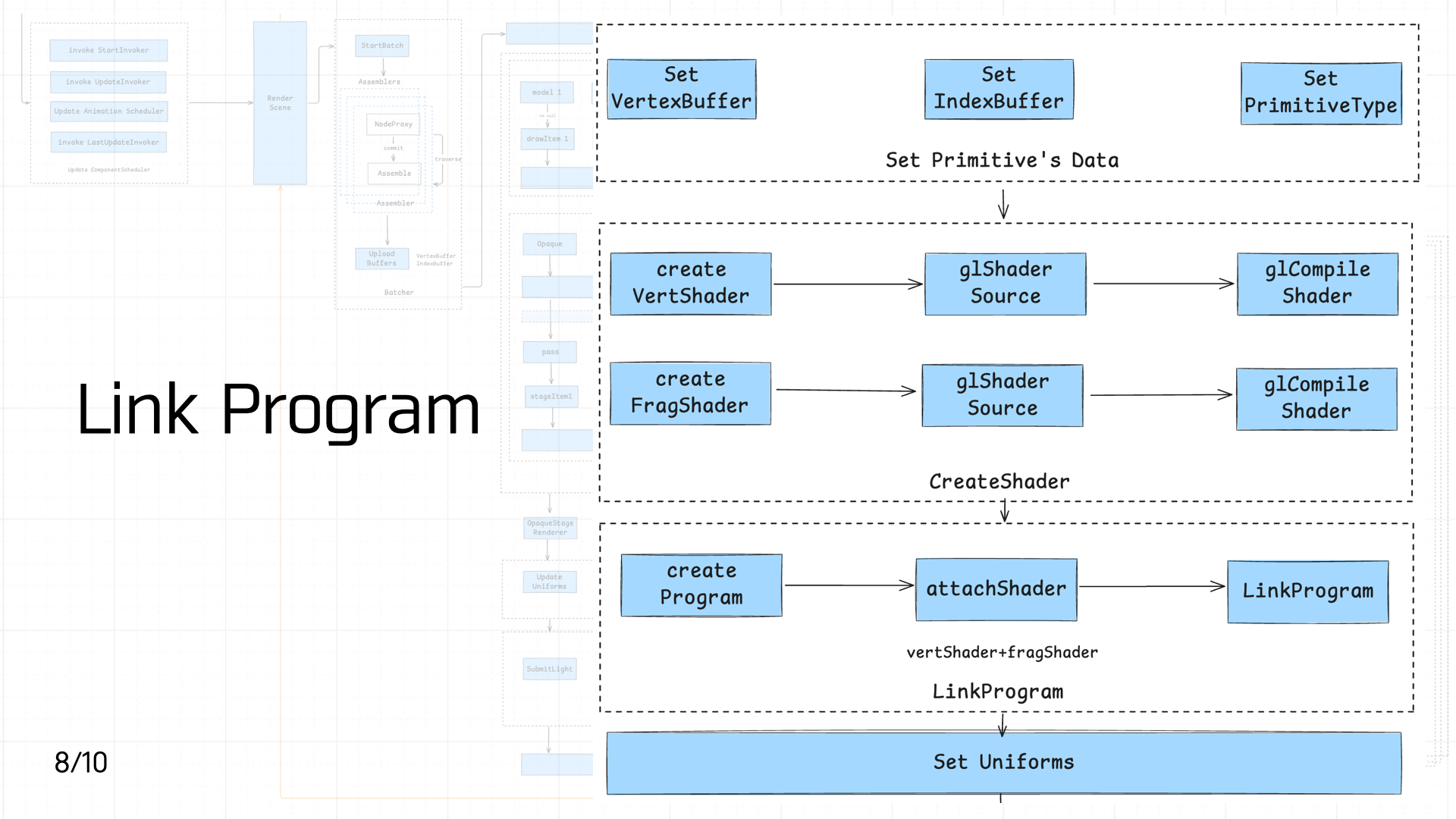
接下来进入到着色器的创建与 Link 阶段,首先是创建图元:
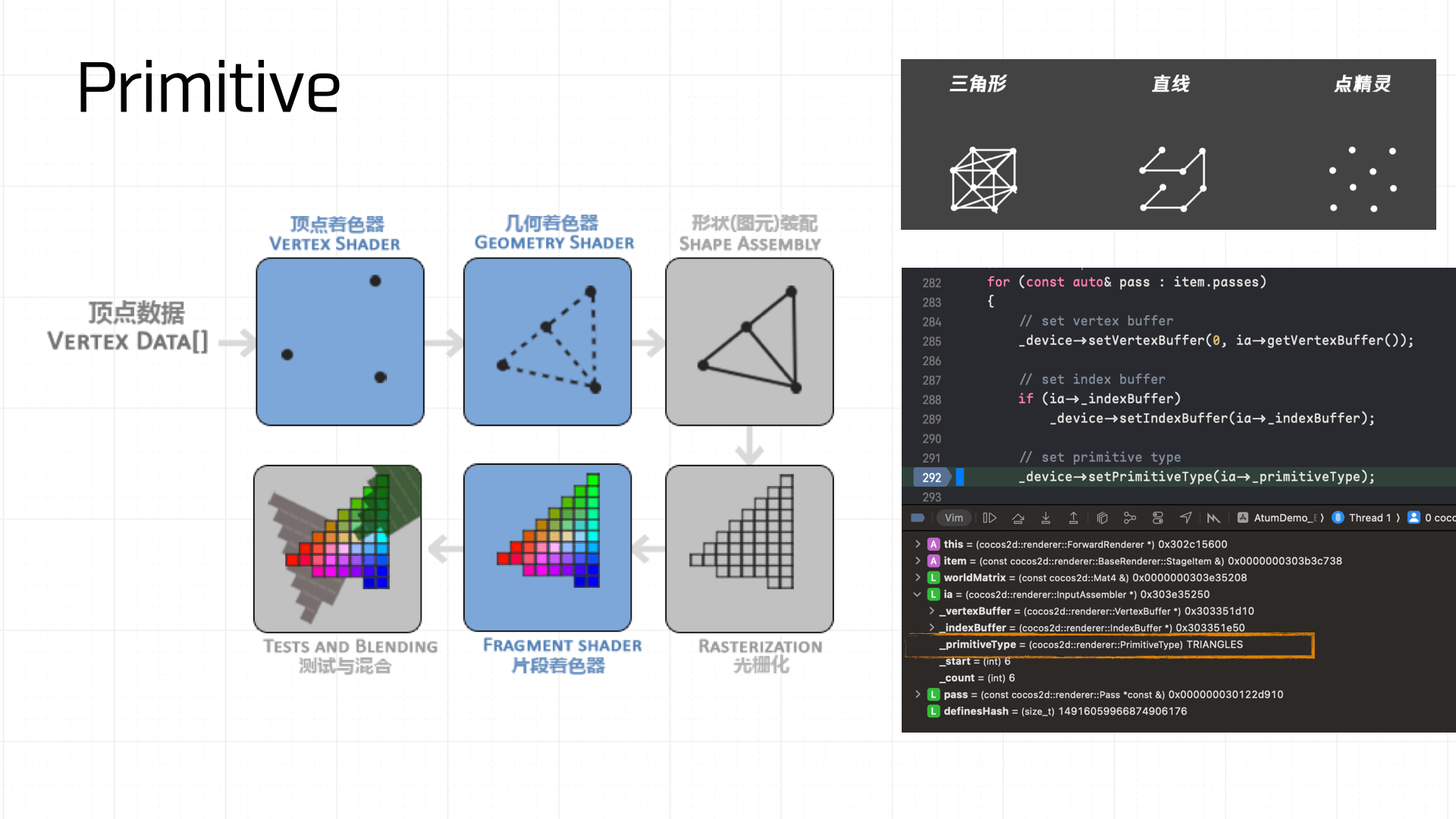
之后是创建顶点着色器和片元着色器:
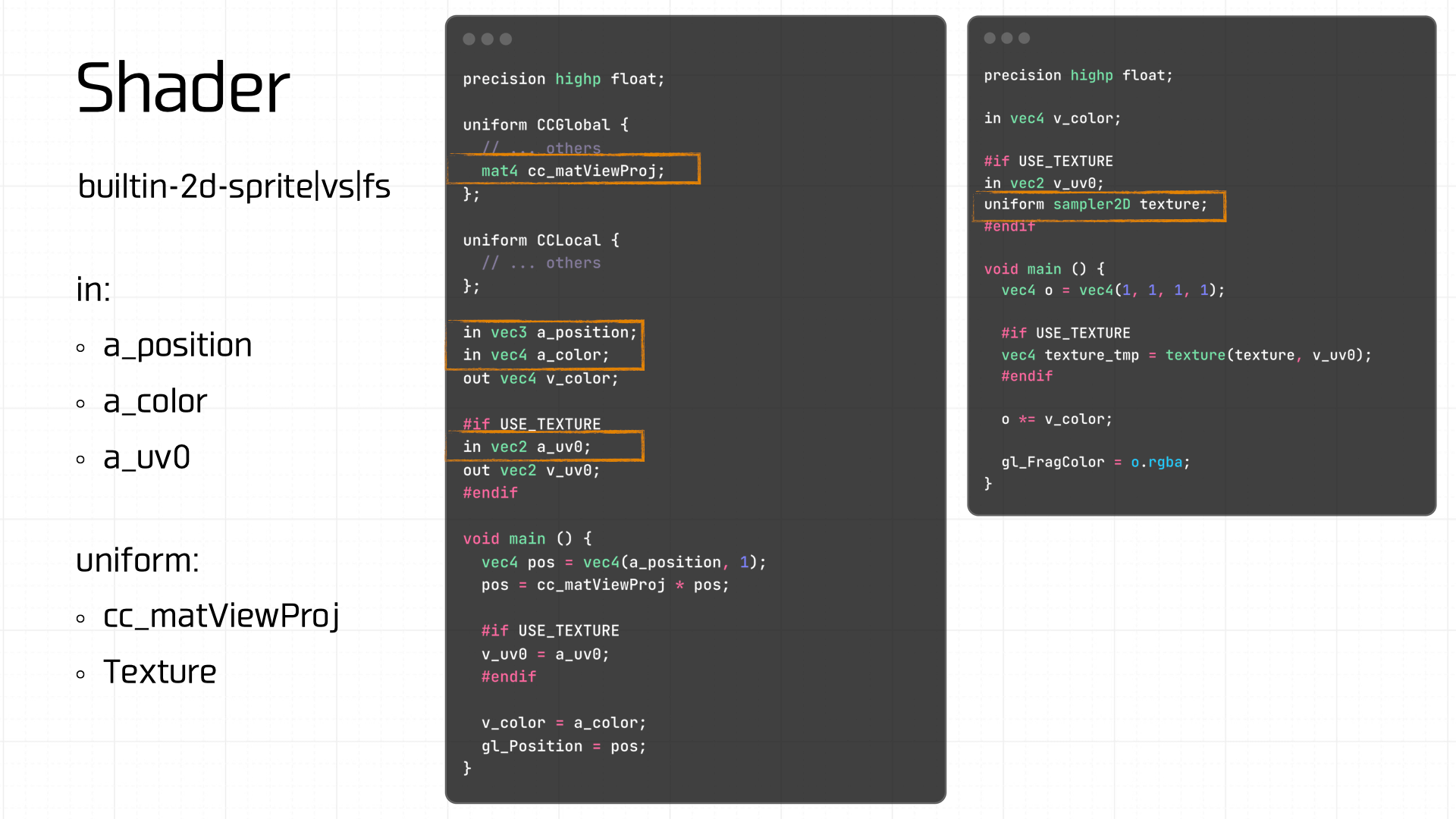
值得关注的是,在 Cocos 中有一共有 11 个内置着色器,其中前 5 个处理 2D 渲染相关,builtin-clear-stencil|vs|fs 用于清楚模板缓冲区,7-10 3D 渲染相关,最后一个用于处理 3D 光照:
- builtin-2d-spine|vs|fs
- builtin-2d-graphics|vs|fs
- builtin-2d-label|vs|fs
- builtin-2d-sprite|vs|fs
- builtin-2d-gray-sprite|vs|fs
- builtin-clear-stencil|vs|fs
- builtin-3d-trail|particle-trail:vs_main|tinted-fs:add
- builtin-3d-trail|particle-trail:vs_main|tinted-fs:multiply
- builtin-3d-trail|particle-trail:vs_main|no-tint-fs:addSmooth
- builtin-3d-trail|particle-trail:vs_main|no-tint-fs:premultiplied
- builtin-unlit|unlit-vs|unlit-fs
文中的 Demo 是使用内置着色器模板进行创建的。
接着创建着色器程序,Link 上我们创建的顶点着色器和片元着色器。紧接着,设置着色器中所需要的 Uniforms 变量,这里就包括纹理和我们上一步计算得到的视图投影矩阵:

最终,我们的 Framebuffer 会附着上颜色附件、深度附件与模板附件:
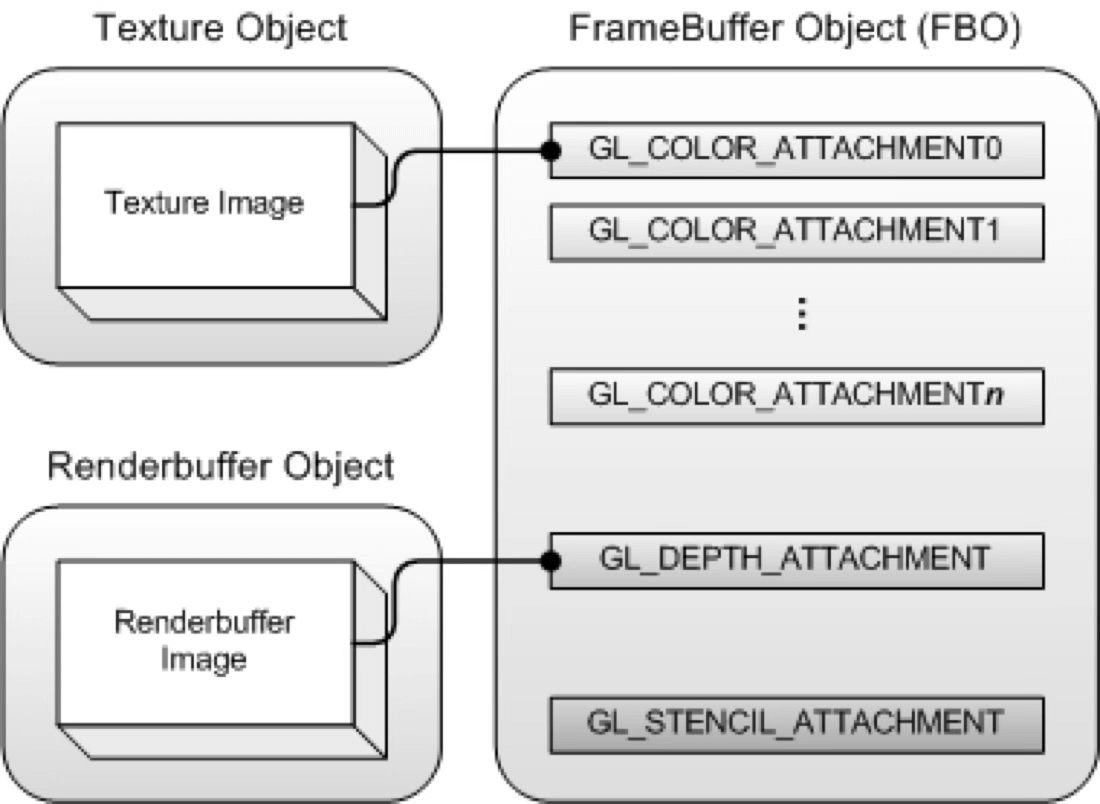
需要注意的是对于刚创建完的 FrameBuffer 不能立即使用,因为它还不完整(Complete)。而一个完整的帧缓冲需要满足以下的条件:
- 附加至少一个缓冲(颜色、深度或模板缓冲)。
- 至少有一个 GL_COLOR_ATTACHMENT。
- 所有的附件都必须是完整的(保留了内存)。
- 若开启 Multisampling,则每个缓冲都应该有相同的样本数(sample)。
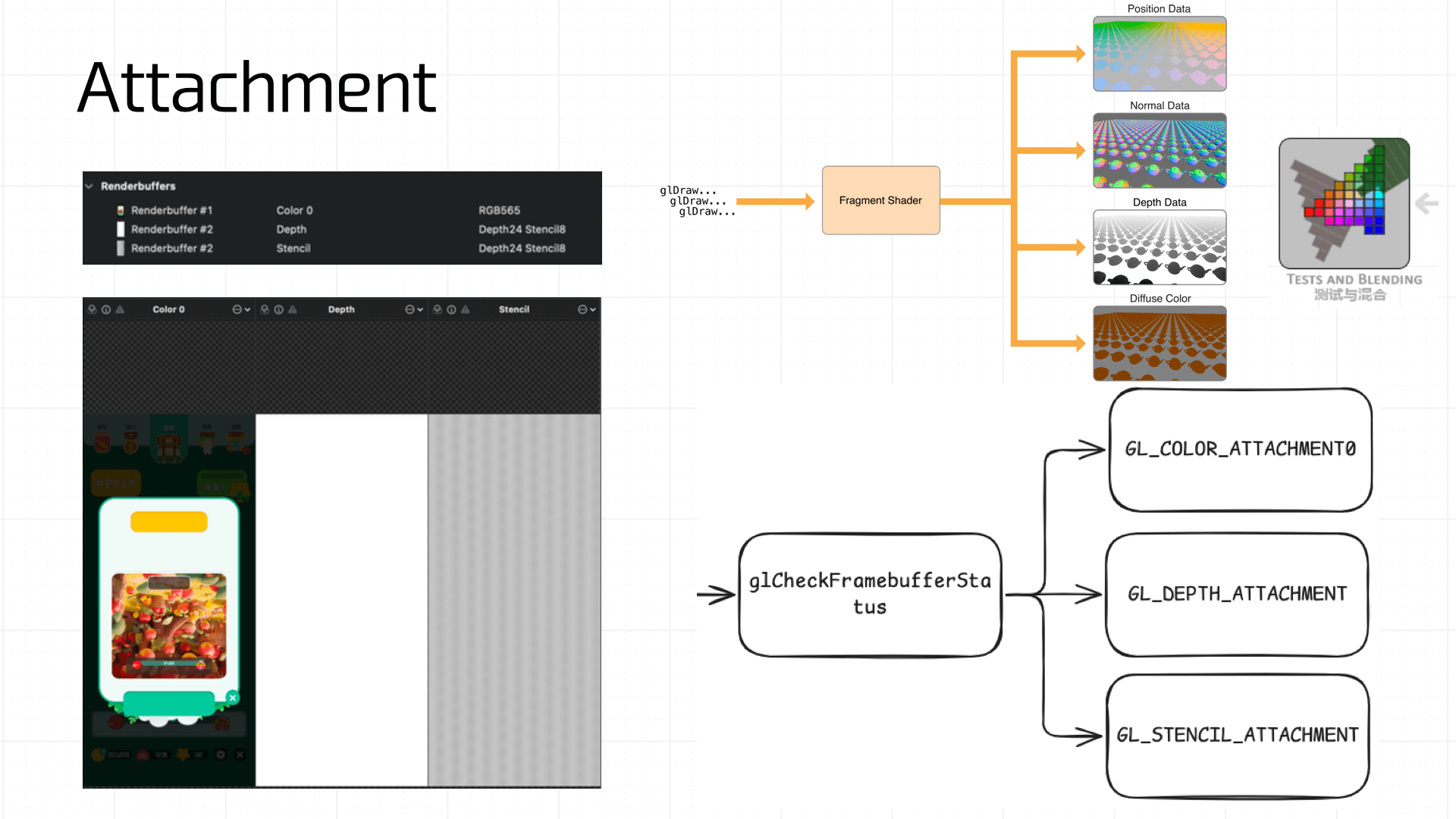
因此需要使用 glCheckFramebufferStatus 对缓冲区的完整性做出检查:
GLenum status = glCheckFramebufferStatus(GL_FRAMEBUFFER);
if (status != GL_FRAMEBUFFER_COMPLETE) {
// ...
// notify native: getInstance()->glErrorCallback(GL_ERROR, errMsg);
return;
}
3.9 Blend & Test
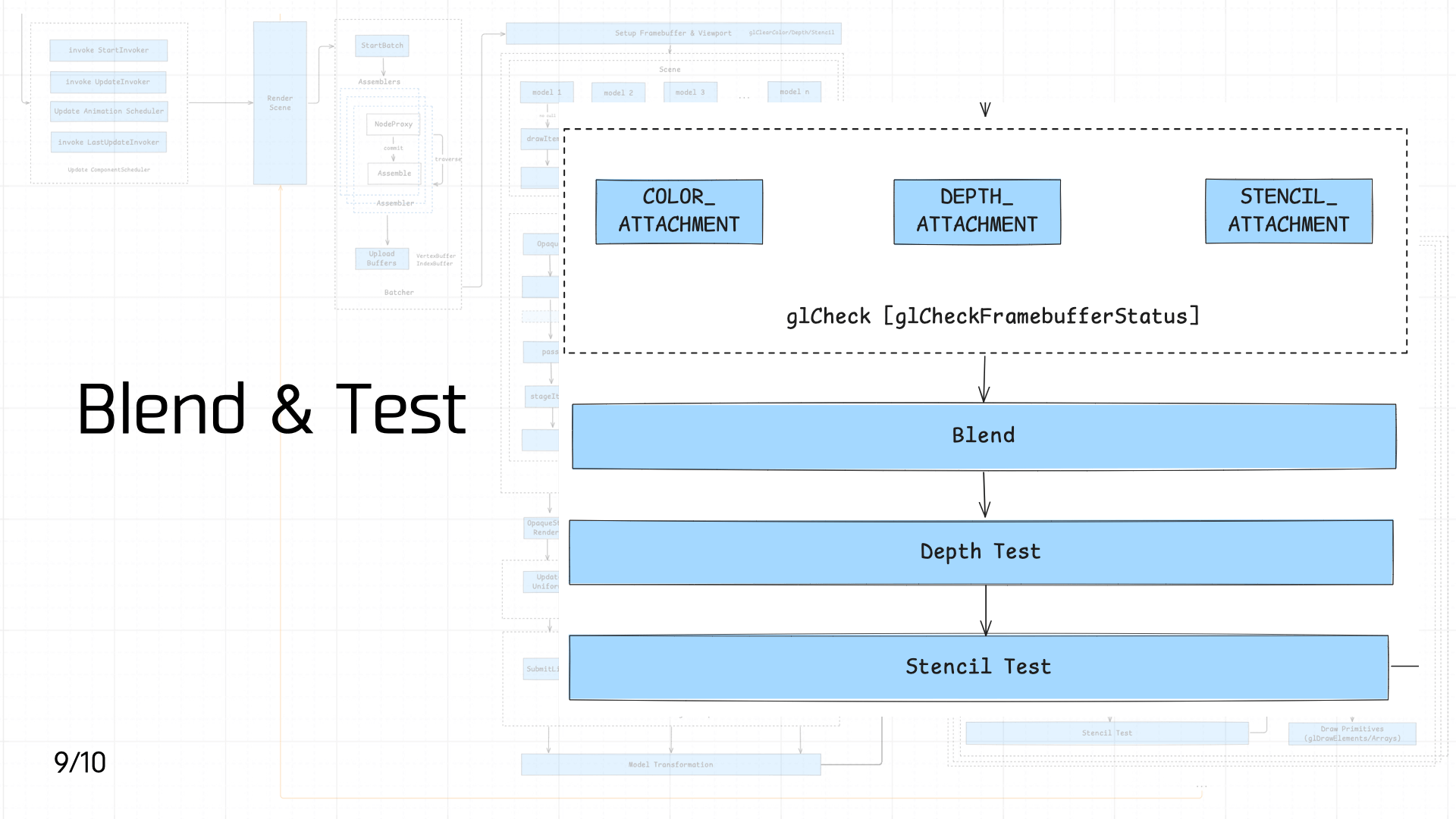
接着依次进入执行 混合(Blend)、深度测试(Depth Test)、模版测试(Stencil Test)。
首先是 Blend,顾名思义讲两个颜色进行混合。下图展示了混合方程的计算方式:
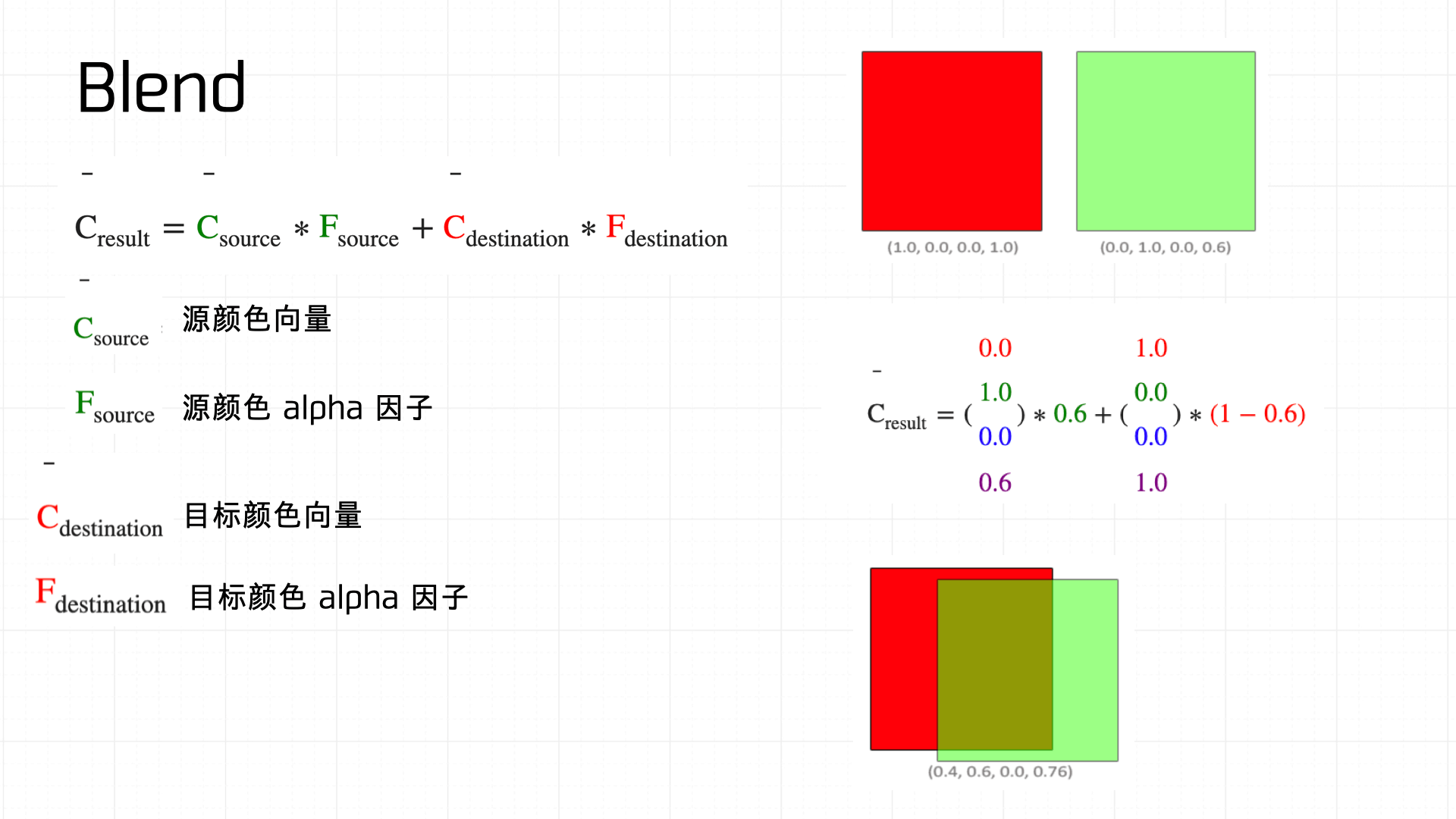
OpenGL 中常用的混合函数如下图所示:

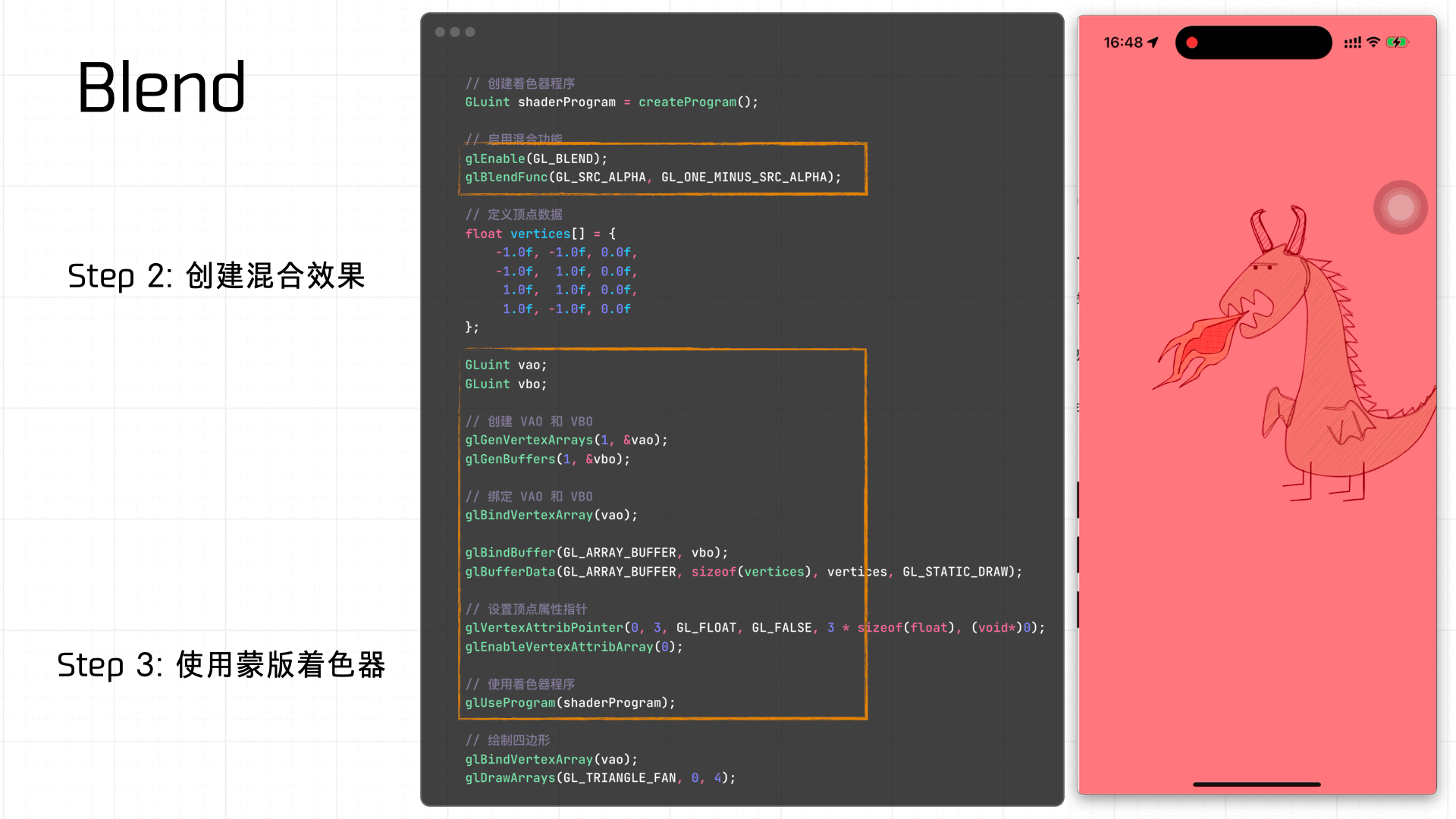
下面是一个简单的例子,使用着色器来创建红色蒙版的 Blend 效果:

深度测试(Depth Test)在图形渲染中用来决定每个像素是否显示。启用深度测试时,OpenGL会将当前片段的深度值与深度缓冲区的值进行比较。如果通过测试,深度缓冲区将更新为新的深度值,否则该片段会被丢弃。下图展示了 OpenGL 中常用的深度测试函数:

而模板测试(Stencil Test)则用于限制渲染区域。通过模板缓冲区,可以在渲染时创建特殊的区域标记,只有符合模板缓冲区设定条件的片段才会被渲染到屏幕上。模板缓冲区允许实现诸如阴影、镜面效果、轮廓高亮等复杂渲染效果。下图展示了 OpenGL 中常用的模版测试函数:

上述的结果最终都会与 Framebuffer 的 Attachment 机制相关联。Framebuffer 的 Attachment 机制决定了渲染结果如何输出到缓冲区中。Framebuffer 通常会附带多个 buffer,包括颜色缓冲区(GL_COLOR_ATTACHMENT)、深度缓冲区(GL_DEPTH_ATTACHMENT)和模板缓冲区(GL_STENCIL_ATTACHMENT),他们共同决定了最终渲染的结果。
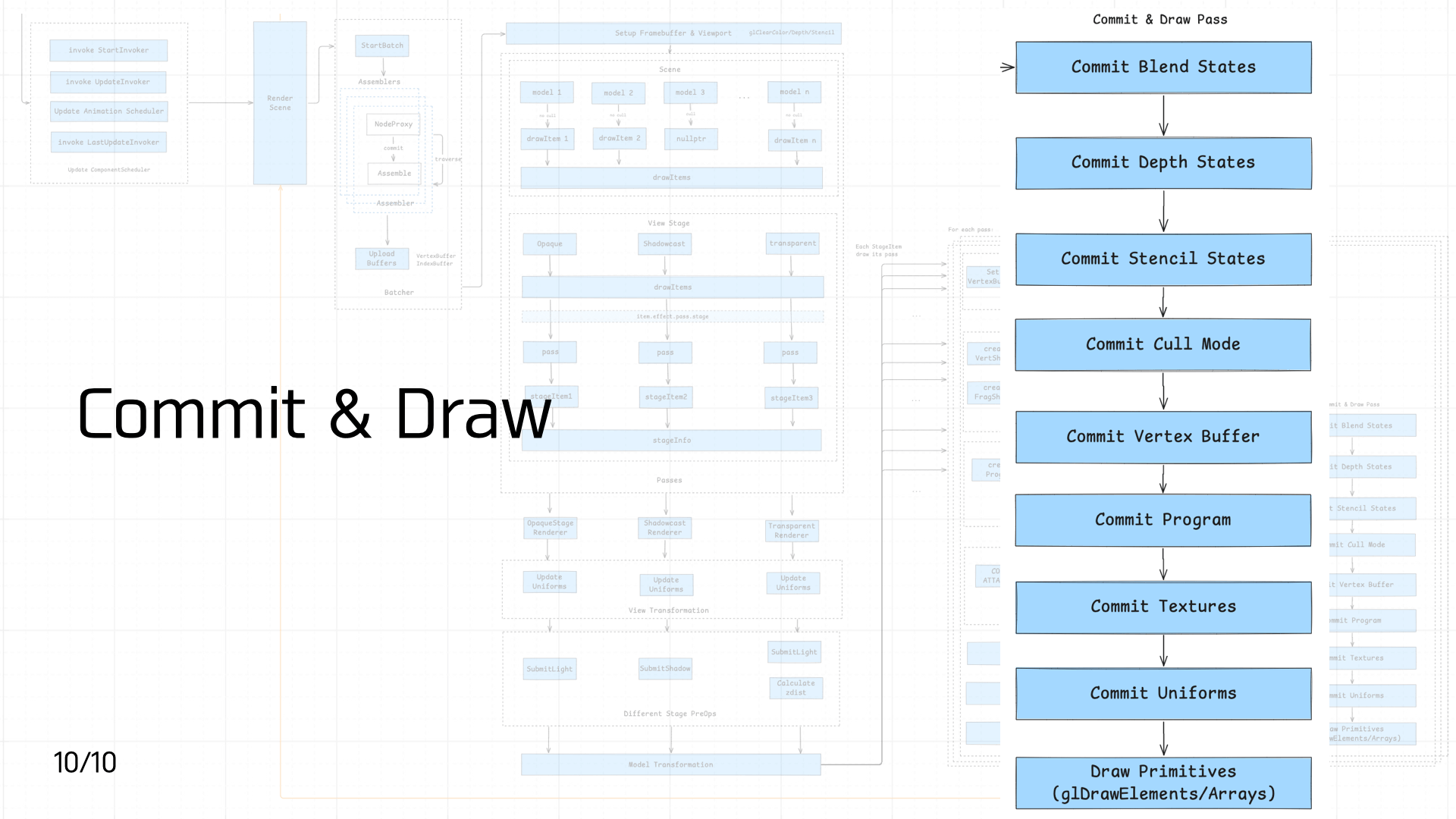
3.10 Commit & Draw Pass
到了管线的最后一步,便是提交(Commit)和绘制(Draw)。
在 Cocos 中每一帧会存储两种状态,一个是当前画面帧的状态(currentState),另一个是我们即将渲染帧的状态(nextState)。
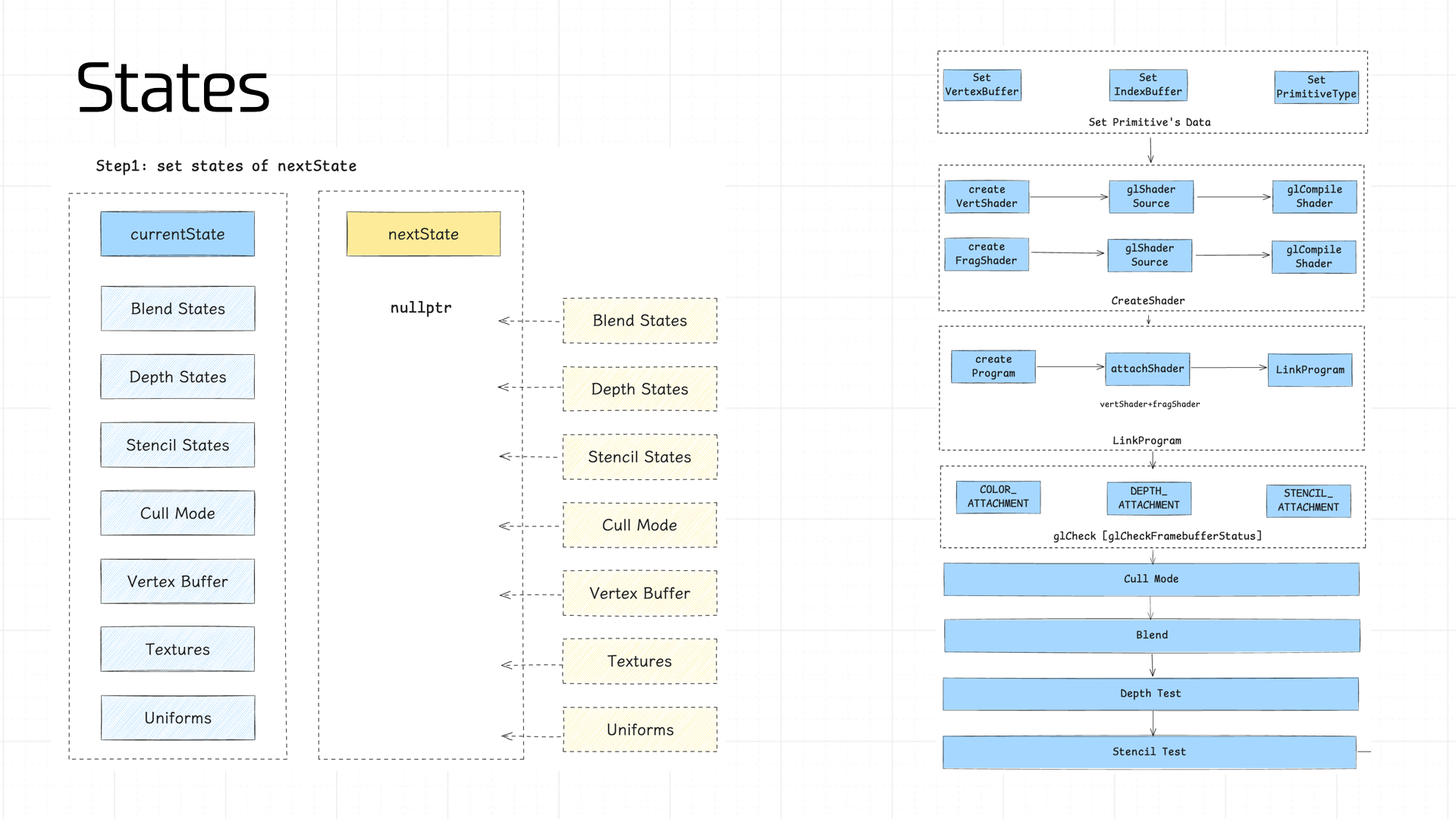
我们需要依次计算 nextState 中的各个部分的 state,之后将 nextState 和 currentState 的状态值做 diff,如果某个环节的状态值不一致,便会触发 commit 操作。以便管线最大程度利用缓存结果。
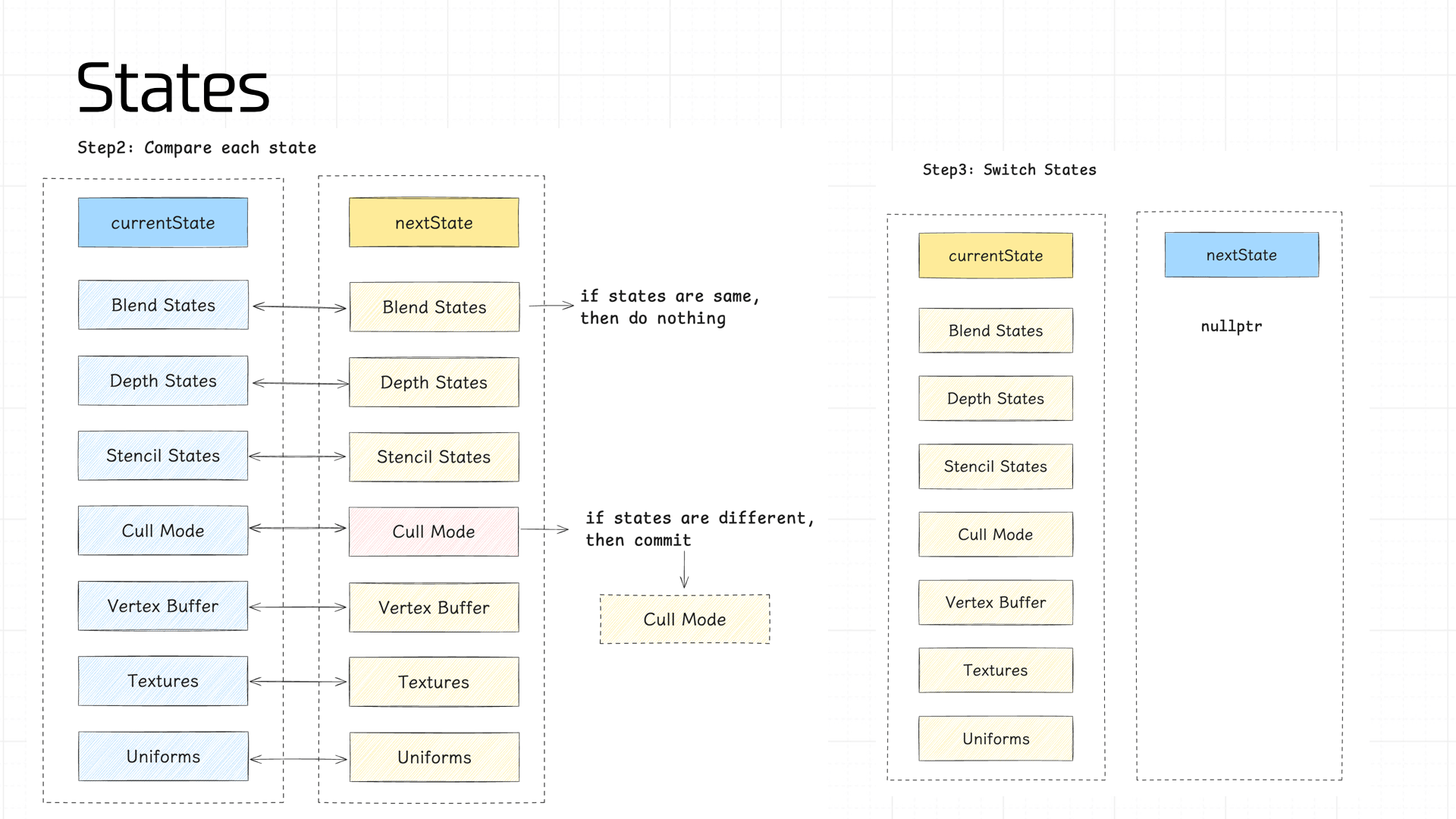
下面依次介绍下管线中需要管理的状态值:
- Blend States、Depth States、Stencil States
- Cull Mode
- Vertex Buffer
- Program
- Textures
- Uniforms
其中 Program 通常在管线初始化时所有的着色器都会准备好,非极端情况下缓存不会失效,因此上面的图中没有标出这个状态。
Blend States、Depth States、Stencil States 分别存储了我们前文所说的 Blend、Depth Test、Stencil Test 过程中涉及到的 GL 调用的参数和部分结果,这里就不详述了。
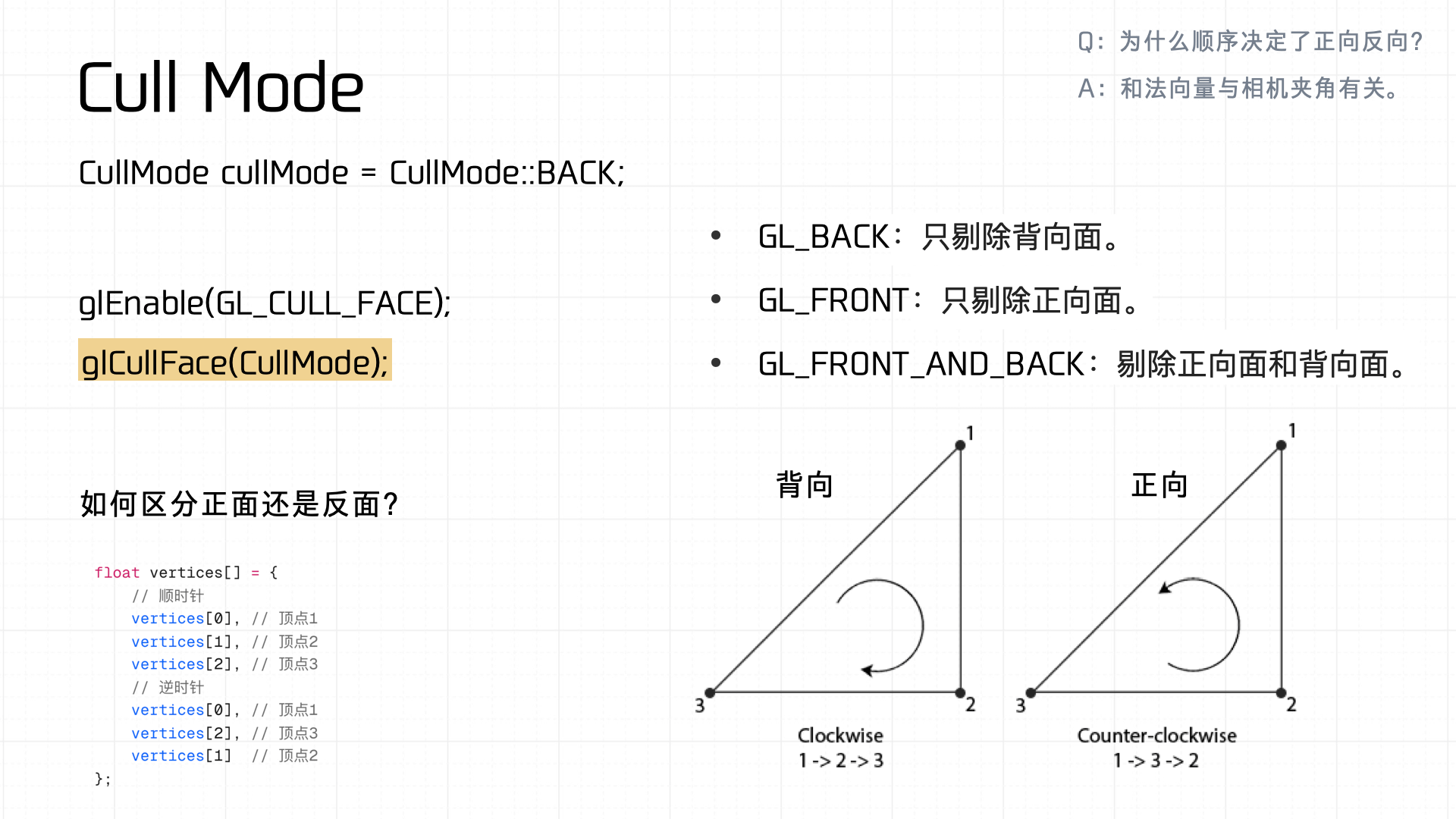
接着是 Cull Mode,根据顶点的索引的顺逆时针来用来区分正面与反面,如果状态值和 currentState 不一样,便触发 glCullFace 的调用来进行 commit。
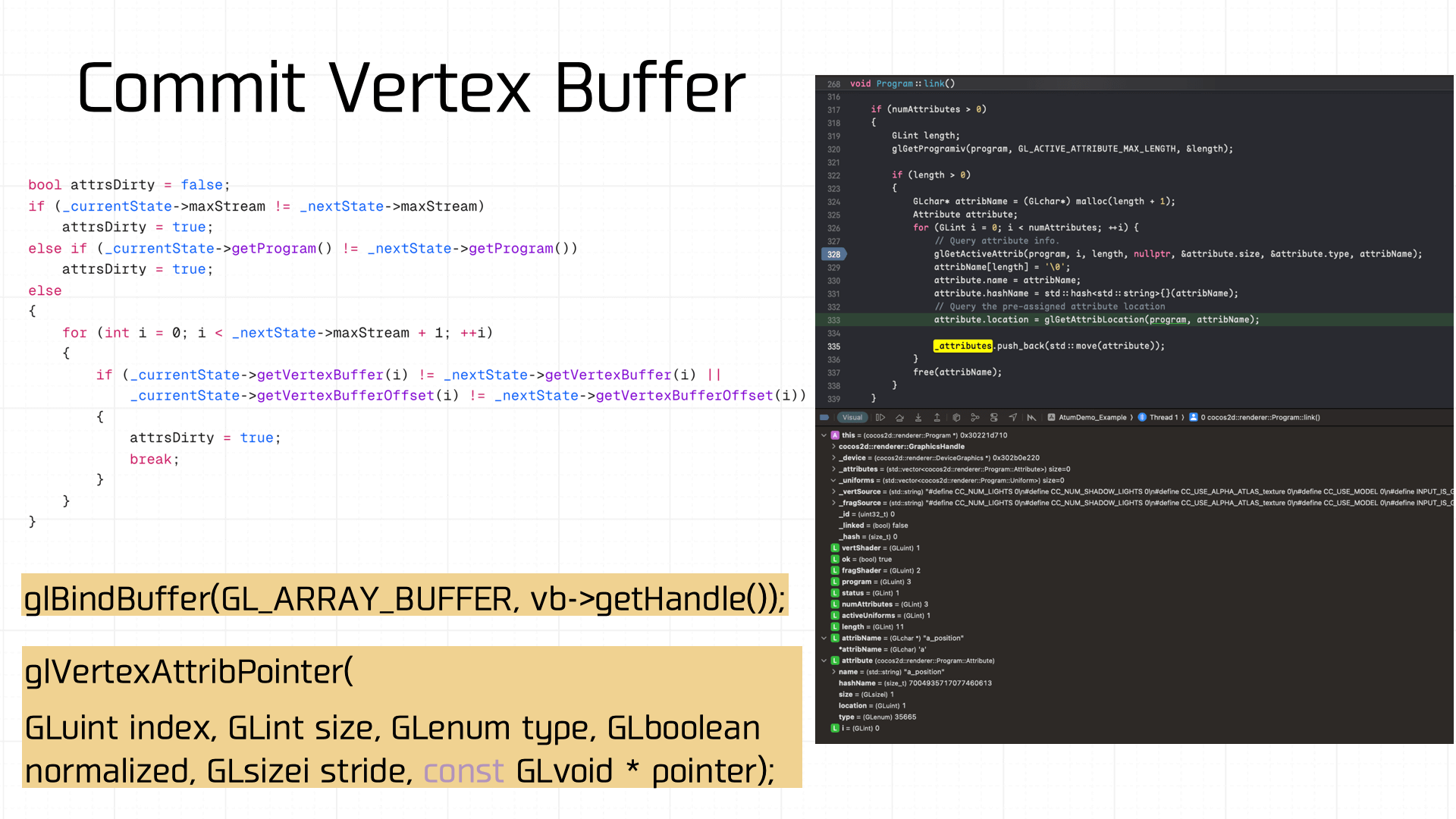
对应顶点缓冲区也是一样有状态值管理,如果变脏了,就需要重新调用 glBindBuffer 进行绑定:
着色器程序也是一样的,如果脏了,就重新调用 glUseProgram 进行设置:

接着便是对 Textures 的检查和提交,这里有两个知识点:
- 纹理的应用:具体涉及到
glActiveTexture和glBindTexture。首先使用glActiveTexture函数来选择当前要激活的纹理单元,这一步决定了接下来绑定的纹理将作用于哪个纹理单元上。然后,通过glBindTexture函数将具体的纹理对象绑定到特定的纹理目标上。通过这种机制,纹理对象与对应的纹理单元和目标进行关联,从而完成纹理的激活与绑定操作。 - 纹理单元:用于表示显卡可以同时管理的多个纹理。默认情况下,
GL_TEXTURE0纹理单元总是被激活的状态。此外,OpenGL 规范保证至少支持 16 个纹理单元(即从GL_TEXTURE0到GL_TEXTURE15)。纹理单元是按顺序定义的,因此我们可以通过诸如GL_TEXTURE0 + 8的方式便捷地访问特定编号的纹理单元,以便在复杂的渲染场景中实现多纹理同时使用。

当前面的状态值都准备并提交完毕后,最后需要管理的状态值是 Uniforms,这一步如果有脏区产生,也需要重新提交 Uniforms 变量。比如游戏 Demo,涉及到的 Uniforms 变量有 cc_matViewProj 和 texture:

最后就是绘制了,其中在每一帧的绘制前都需要调用 glClear 清理 Freambuffer 的状态。下图展示了 gl 指令调用的时序:
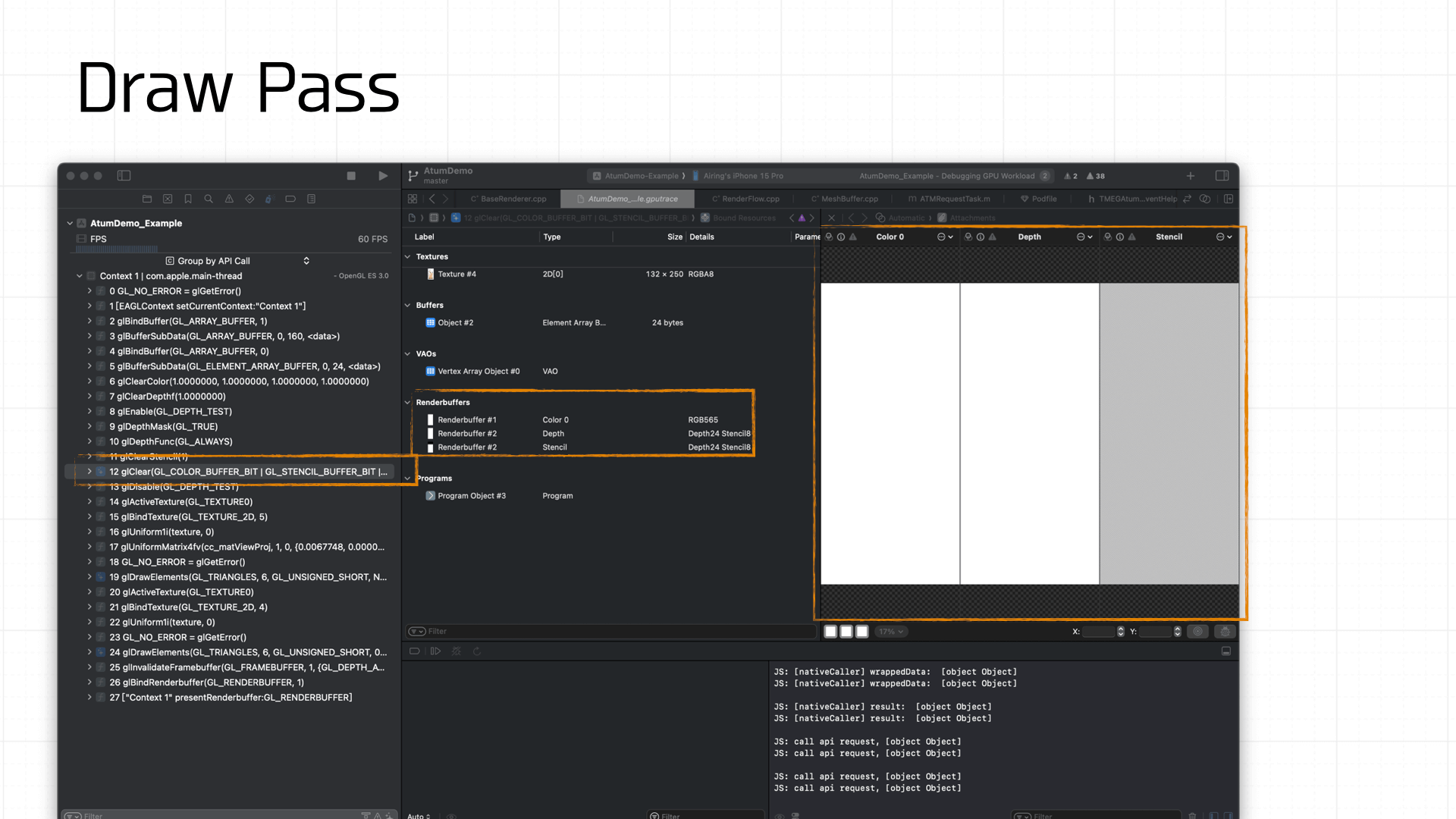
由于游戏 Demo 比较简单,绘制只需要准备好纹理和 Uniforms 即可,最后调用 glDrawArrays 或 glDrawElements 将准备好 Framebuffer 绘制上屏:
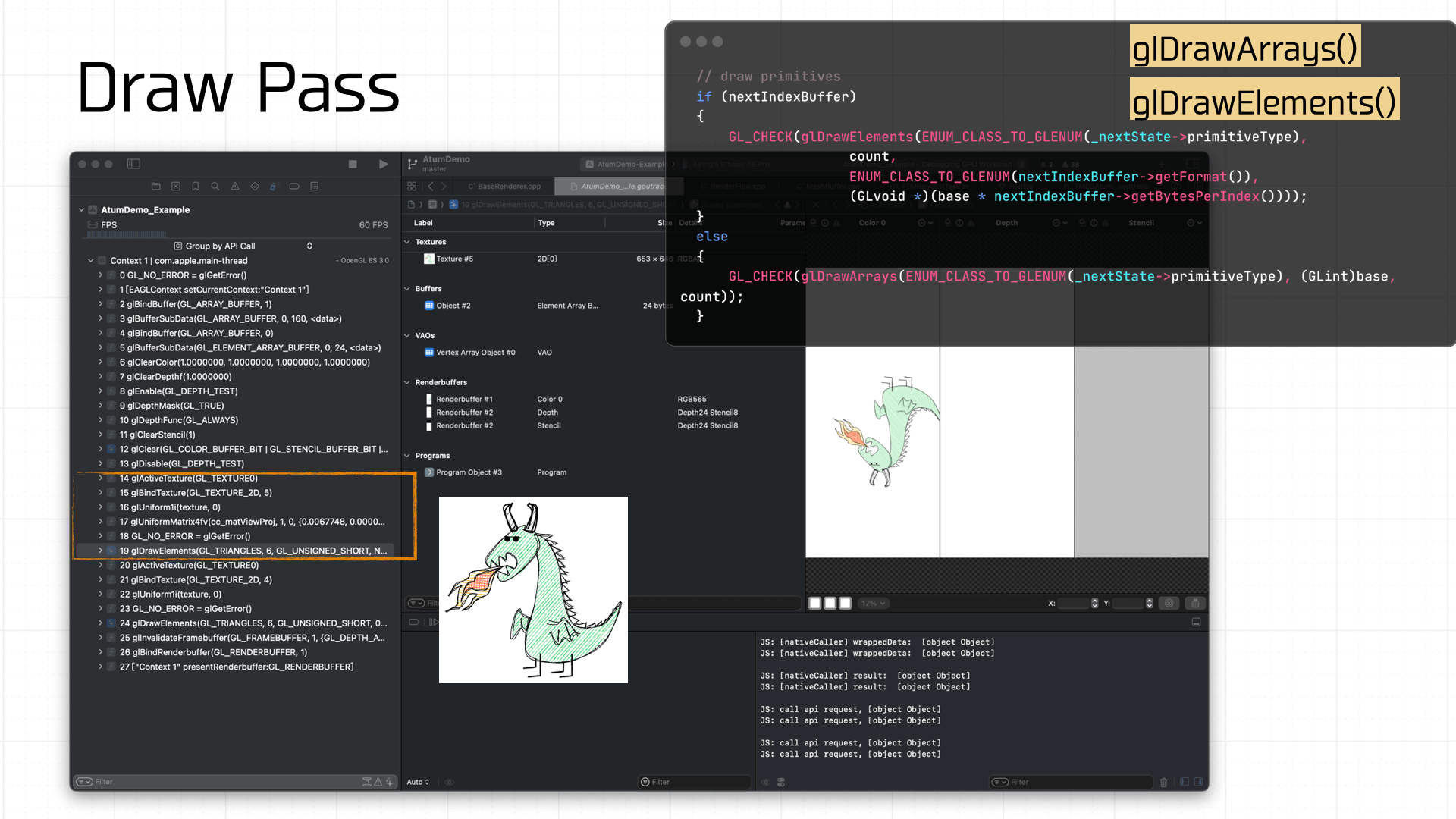
至此,经历了这一系列的管线处理之后,我们的 Demo 游戏在小游戏容器内完成了上屏。
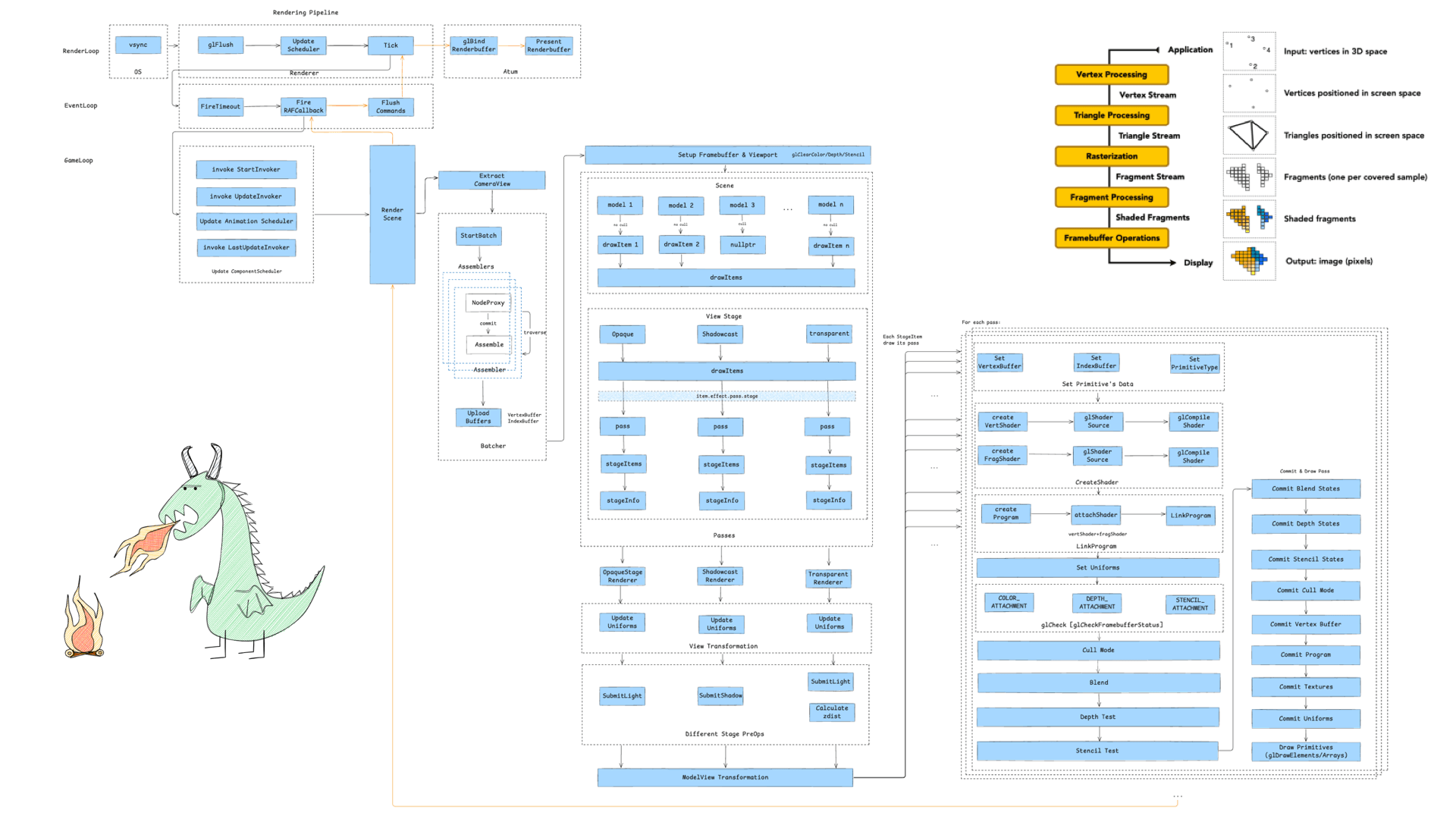
扩展阅读
- 《GAMES 101》
- 《计算机图形学入门:3D渲染指南》
- 《
LearnOpenGL 》